От правильности выбора файла-эталона зависит корректность результатов распознавания. Например, если файл не содержал какого-либо символа, то, согласно алгоритму обучения, вес этого символа при распознавании всегда будет равен нулю. Для уменьшения возможных ошибок такого рода (которые могут появиться вследствие неудачного выбора файла-эталона) программа производит запись нулевых весов не как 0, а как очень маленькое число (1×10-30). Диалог обучения нейронной сети представлен на рис.9.
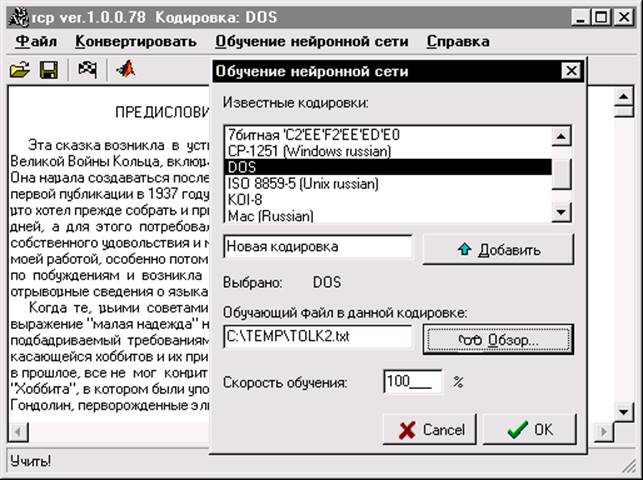
Рисунок 9 Диалог обучения нейронной сети
Программа включает в себя систему справки, в которой содержатся рекомендации по настройке, использованию, обучению программы, а также сведения об авторе (рис.10,11).
Рисунок 10 Справка RCP. Сведения о программе и авторе
Рисунок 11 Справка RCP. Рекомендации по настройке программы
Приложение RCP использует в своей работе два типа файлов:
· таблицы перекодировок;
· таблицы весов.
Файлы таблиц весов создаются самой программой в режиме обучения нейронной сети. Эти файлы имеют расширение wt и содержат веса каждого символа в текстах соответствующего типа. Фрагмент файла весов для кодировки “KOI-8”:
1,00000000317108E-30
1,00000000317108E-30
0,00030473992228508
6,12747862760443E-6
0,000729986932128668
6,49512730888091E-5
0,000409315573051572
6,9444754444703E-6
1,1029461347789E-5
0,00136847025714815
0,0153472907841206
0,000461603369330987
0,00111765204928815
0,0168636385351419
Номер веса в файле соответствует коду символа в данной кодировке.
Формат файла таблицы перекодировок (с расширением tbl) совпадает с файлом, который может быть получен путем сохранения настроек кодировок FAR-а (The FAR manager, Copyright (C) Eugene Roshal) в *.reg-файл. Каждый код в таком файле ставит в соответствие символу кодировки соответствующий ASCII-код. Например, если в файле написан код D8h в позиции 145 (91h) (он является 145-м кодом по счету с начала файла), то это означает, что для того, чтобы перекодировать символ с кодом D8h из ASCII в данную кодировку, необходимо заменить его на символ с кодом 91h. Коды символов в файле должны быть записаны в hex-виде двумя символами. Отделяться друг от символы могут любыми символами (кроме цифр и символов 'A' - 'F' и 'a' - 'f'). Можно и вообще не отделять в файле символы один от другого, но основное условие должно соблюдаться - каждый код записывается двумя hex символами (01, 02, 0F, 8D и т.п.).
Пример строк из файла кодировки "CP-1251 (Windows russian)":
00,01,02,03,04,05,06,07,08,09,0a,0b,
0c,0d,0e,0f,10,
11,12,13,
14,15,16,17,18,19,1a,1b,1c,1d,... и т.д.
В данной курсовой работе я разработал программу для распознавания различных кодировок русских текстов. Основой программы является нейронная сеть, использование которой дает программе ряд преимуществ:
1. гибкость;
2. способность обучаться;
3. нечувствительность к мелким погрешностям во входных данных.
К достоинствам программы можно отнести высокую скорость (за счет быстрых алгоритмов обучения нейронной сети и применяемых средств разработки), достаточную достоверность результатов, простоту в обращении.
Недостатками являются:
· малая достоверность результатов распознавания, если входной файл малого размера. Это объясняется тем, что невозможно достоверно посчитать частоту встречаемости тех или иных символов в таком файле. Это частично устраняется путем дополнительного обучения, но, как и у всех подобных программ, полностью устранить этот недостаток не удается;
· малая достоверность результатов распознавания файлов со значительными примесями других кодировок, цифр и псевдографики.
1. А.И. Змитрович. Интеллектуальные информационные системы. Мн: ТетраСистемс, 1997.
2. Л.Б. Емельянов-Ярославский. Интеллектуальная квазибиологическая система. Индуктивный автомат. М: Наука, 1990.
3.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.