



При изучении полнотекстовых запросов важно знать, какие есть средства, способные помочь находить ошибки в возвращаемых результатах запросов и анализировать полученные результаты. Необходимо понимать, как обработчик полнотекстового поиска будет интерпретировать конкретный запрос.
Если выполнить полнотекстовый поиск до завершения полнотекстового заполнения, запрос может вернуть только часть совпадающих строк.
Полнотекстовые индексы по умолчанию обновляются автоматически по мере изменения данных в связанных с ними таблицах. Также обновлять полнотекстовые индексы можно вручную либо по заданному расписанию.
Для того чтобы определить состояние операции заполнения полнотекстового каталога, можно использовать функцию FULLTEXTCATALOGPROPERTY, например:
FULLTEXTCATALOGPROPERTY ('[Каталог]','PopulateStatus')
Функция возвращает: 0 = бездействие
1 = выполняется полное заполнение
2 = приостановлено
3 = ожидание истечения интервала повтора
4 = восстановление
5 = выключение
6 = выполняется добавочное заполнение
7 = построение индекса
8 = диск заполнен, приостановлено.
9 = отслеживание изменений
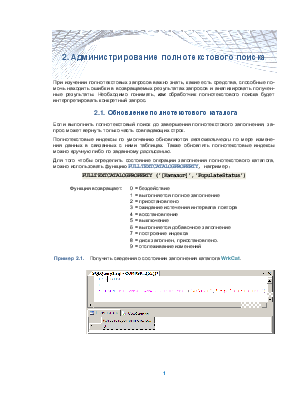
Пример 2.1. Получить сведения о состоянии заполнения каталога WrkCat.
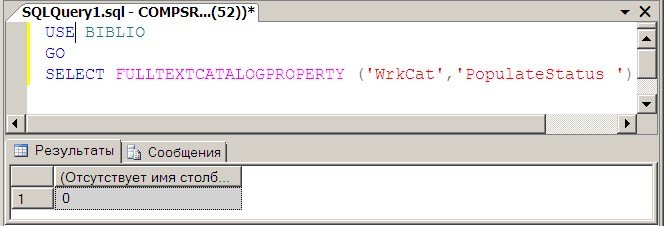
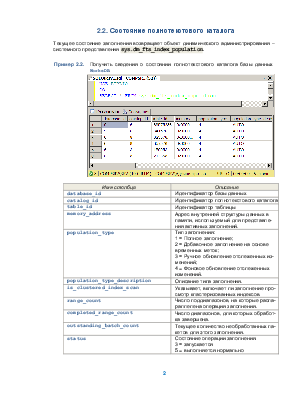
Текущее состояние заполнения возвращает объект динамического администрирования – системного представления sys.dm_fts_index_population.
Пример 2.2. Получить сведения о состоянии полнотекстового каталога базы данных WorksDB.
|
Имя столбца |
Описание |
|
database_id |
Идентификатор базы данных |
|
catalog_id |
Идентификатор полнотекстового каталога |
|
table_id |
Идентификатор таблицы |
|
memory_address |
Адрес внутренней структуры данных в памяти, используемый для представления активных заполнений. |
|
population_type |
Тип заполнения: 1 = Полное заполнение; 2 = Добавочное заполнение на основе временных меток; 3 = Ручное обновление отслеженных изменений; 4 = Фоновое обновление отслеженных изменений. |
|
population_type_description |
Описание типа заполнения. |
|
is_clustered_index_scan |
Указывает, включает ли заполнение просмотр кластеризованных индексов. |
|
range_count |
Число поддиапазонов, на которые распараллелена операция заполнения. |
|
completed_range_count |
Число диапазонов, для которых обработка завершена. |
|
outstanding_batch_count |
Текущее количество необработанных пакетов для этого заполнения. |
|
status |
Состояние операции заполнения. 3 = запускается 5 = выполняется нормально |
|
7 = обработка остановлена 11 = заполнение прервано |
|
|
status_description |
Описание состояния заполнения. |
|
completion_type |
Состояние завершения данного заполнения. |
|
completion_type_description |
Описание типа завершения. |
|
worker_count |
Значение всегда равно 0. |
|
queued_population_type |
Тип заполнения на основе отслеженных изменений, которое последует за текущим заполнением, если таковое выполняется. |
|
queued_population_type_descriptio n |
Описание следующего заполнения, оно должно произойти. |
|
start_time |
Время начала заполнения. |
|
incremental_timestamp |
Для полного заполнения содержит временную метку его начала. |
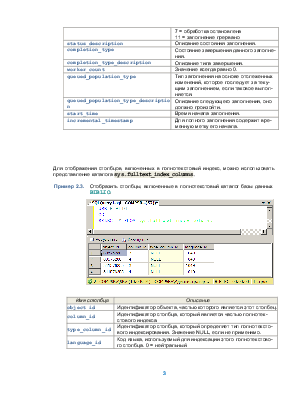
Для отображения столбцов, включенных в полнотекстовый индекс, можно использовать представление каталога sys.fulltext_index_columns.
Пример 2.3. Отобразить столбцы, включенные в полнотекстовый каталог базы данных BIBLIO.
|
Имя столбца |
Описание |
|
object_id |
Идентификатор объекта, частью которого является этот столбец. |
|
column_id |
Идентификатор столбца, который является частью полнотекстового индекса. |
|
type_column_id |
Идентификатор столбца, который определяет тип полнотекстового индексирования. Значение NULL, если не применимо. |
|
language_id |
Код языка, используемый для индексации этого полнотекстового столбца. 0 = нейтральный |
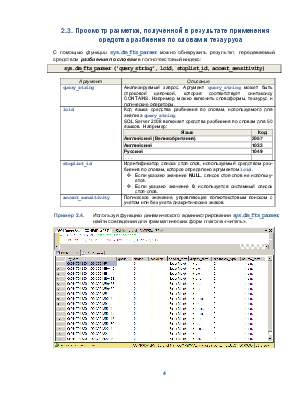
С помощью функции sys.dm_fts_parser можно обнаружить результат, передаваемый средством разбиения по словам в полнотекстовый индекс:
sys.dm_fts_parser ('query_string', lcid, stoplist_id, accent_sensitivity)
|
Аргумент |
Описание |
|||
|
query_string |
Анализируемый запрос. Аргумент query_string может быть строковой цепочкой, которая соответствует синтаксису CONTAINS. Например, можно включить словоформы, тезаурус и логические операторы. |
|||
|
lcid |
Код языка средства разбиения по словам, используемого для анализа query_string. SQL Server 2008 включает средства разбиения по словам для 50 языков. Например: |
|||
|
Язык |
Код |
|||
|
Английский (Великобритания) |
2057 |
|||
|
Английский |
1033 |
|||
|
Русский |
1049 |
|||
|
. . . |
||||
|
stoplist_id |
Идентификатор списка стоп-слов, используемый средством разбиения по словам, которое определено аргументом lcid. v Если указано значение NULL, список стоп-слов не используется. v Если указано значение 0, используется системный список стоп-слов | |||
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.