Примерами стопслов для английского языкового стандарта могут служить слова «a», «and», «is» и «the». Эти слова игнорируются во избежание чрезмерного увеличения полнотекстового индекса.
• Список стоп-слов
Списки стоп-слов взаимосвязаны с полнотекстовыми индексами и применяются при полнотекстовых запросах по этим индексам.
Архитектура полнотекстового поиска состоит из следующих процессов: ♦ Процесс SQL Server (sqlservr.exe).
♦ Процесс узла управляющей программы фильтрации (fdhost.exe).
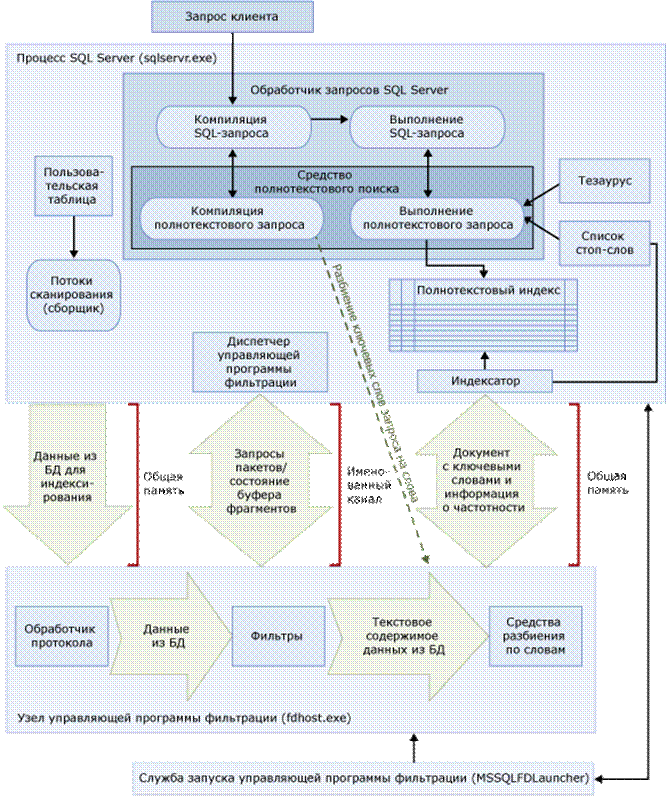
В полнотекстовом поиске используются следующие компоненты процесса SQL Server:
• Пользовательские таблицы.
В этих таблицах содержатся данные, по которым осуществляется полнотекстовое индексирование.
• Средство сбора полнотекстовых данных
Полнотекстовое средство сбора данных работает с потоками полнотекстового сканирования. Оно отвечает за планирование заполнения полнотекстовых индексов и управление им, а также за наблюдение за полнотекстовыми каталогами.
• Файлы тезауруса
Эти файлы содержат синонимы искомых термов.
• Объекты списка стоп-слов
Объекты списка стоп-слов содержат список часто встречающихся слов, бесполезных при поиске.
• Обработчик запросов SQL Server
Обработчик запросов компилирует и выполняет SQL-запросы. Если SQL-запрос включает запрос полнотекстового поиска, то запрос направляется в средство полнотекстового поиска как в процессе компиляции, так и при выполнении. Результат запроса сопоставляется с полнотекстовым индексом.
• Средство полнотекстового поиска для процесса SQL Server
Средство полнотекстового поиска в SQL Server полностью интегрировано в обработчик запросов. Средство полнотекстового поиска компилирует и выполняет полнотекстовые запросы. Как часть выполнения запроса средство полнотекстового поиска может получать входные данные из тезауруса и списка стоп-слов.
• Модуль записи индекса (индексатор)
Модуль записи индекса строит структуру, используемую для хранения индексированных лексем.
• Диспетчер управляющей программы фильтрации
Диспетчер управляющей программы фильтрации отвечает за наблюдение за состоянием узла управляющей программы фильтрации для полнотекстового поиска.
Узел управляющей программы фильтрации запускает следующие компоненты полнотекстового поиска, которые отвечают за доступ, фильтрацию и разбиение по словам данных из таблиц, а также разбиение по словам и морфологический поиск во входных данных запроса:
• Обработчик протокола.
Этот компонент запрашивает данные из памяти для дальнейшей обработки и обращается к данным из пользовательской таблицы в указанной базе данных.
• Фильтры.
Фильтры извлекают поток текстовых данных из документа с отбрасыванием всех нетекстовых данных и данных о форматировании.
• Средства разбиения по словам и парадигматические модули
Эти компоненты осуществляют лингвистический анализ всех полнотекстовоиндексированных данных. Средство разбиения по словам определяет местонахождение границ слова в потоке текста в строке или документе, для которого строится полнотекстовый индекс. Парадигматический модуль извлекает основную форму слова. Например, слова «бежит», «бежал» и «бегут» являются формами слова «бежать». Средство полнотекстового поиска вызывает парадигматические модули при выполнении запросов, если запрос является запросом FREETEXT или
FREETEXTTABLE, либо в случае, когда запрос требует флективного расширения.
Несмотря на то, что, как правило, настраивает полнотекстовые индексы и управляет ими администратор базы данных, вы как разработчик базы данных должны иметь базовое представление о том, как активизировать и настроить полнотекстовый поиск.
Администрирование полнотекстового поиска можно разделить на четыре основные задачи.
1. Создание полнотекстовых индексов и полнотекстовых каталогов.
2. Изменение существующих полнотекстовых индексов и каталогов.
3. Удаление существующих полнотекстовых индексов и каталогов.
4. Создание расписания заполнения индексов и его обслуживание
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.