1.Ссылочные типы данных.
Ссылка в статической памяти, данные в динамической.
-Раздел кода
-Статическая секция
Свободная память – динамическая память.
Память выделяет диспетчер памяти.
переменная ссылочного типа занимает 4 байта – это под адрес в оперативной памяти.
За каждой переменной закреплён базовый тип. Там может быть скалярный или любой другой тип за исключением файлового.
 Ссылочный
тип ->
Ссылочный
тип ->
type C=^integer;
var A:C;
A – ссылка или указатель. она будет иметь значение, где будет иметь значение адреса памяти, где будет объект целого типа.
2. Оператор NEW.
new(A); {A – переменная ссылочного типа. }
При выполнении процедуры new подаётся запрос диспетчеру памяти. После адрес свободной памяти присваивается переменной.
A – адрес
A^:= 5; A – 4 байта статической памяти и 2 байта динамической.
A1: integer;
A1:=7; A1 – 2 байта статической.
Пример:
type
D = record
fio:string[45]; \ - 107 байт (105 байт символы + 2 модификатора)
adr:string[60]; /
end;
C1=^D;
var
A2:C1;
begin
new(A2);
dispose(A); - освобождение памяти.
Для случая, когда базовый тип – запись с вариантами, процедуры new и dispose выглядят так:
new(A, M1, M2, M3, ... ,MN);
dispose(A, M1, M2, M3, ... ,MN);
Где A – это указатель на запись с вариантами, а M1, M2, M3, ... ,MN – перечисление всех полей записи.
В данн ом случае выделяется маскимально возможное количество байт, которые может занять запись с учётом всех вариантов, а не память под все поля.
При записи:
new(A);
A^:=5;
new(A);
A^:=6;
В памяти будут храниться оба числа, но адрес, где хранится число 5 будет потерян и очищение этой памяти будет только после завершения работы программы.
3. Сортировка данных в динамической памяти.
При сортировке данных в динамической памяти, меняются только значения указателей на следующие/предыдущие поля. Т.е. если цепочка 1—3 — 2, то указатель у 1.след меняется на 2, указатель у 2.след меняется на 3, а указатель 3.след обнуляется.
4. Файлы с прямым доступом.
Массив данных – в памяти.
Набор данных – на диске.
Файл – понятие логическое, которое используется для представления набора данных в программе.
var F:File of real;
read(F,A); - прочитать компонент из файла и записать в переменную. Тип одинаковый!
assign(ифп, спец); - привязать имя файла к файловой переменной.
ифп – переменная спец – путь к файлу C:\A\B\...\a.txt
reset(F); - открыть файл для чтения и добавления компонентов в конец файла. ????
rewrite(F); - открыть файл для перезаписи (содержимое удаляется).
seek(ифп, №); - переходит к определённомукомпоненту в файле.
№ - номер блока, начинается с нуля. Т.е. seek(F,3) – Переход к 4 компоненту.
truncate(ифп); - для отсечения хвостовой части файла начиная от текущего положение указателя включая текущий компонент.
filesize(ифп); - количество компонентов.
filepos(ифп); - текущее значение указателя.
Первое поле в компоненте – ноль.
1) отсортировано
2) без пропусков номера (ключевое поле без пропусков).
Способы формирования:
1) Добавлять попорядку
2) Добавить все компоненты пустыми и обрабатывать.
5. Нетипизированные файлы.
var F:File;
Открытие нетипизированных файлов.
reset(F, 200);
rewrite(F, 200);
200 – размер элемента буфера в байтах. По умолчанию 128 байт.
Скорость чтения с дисков обеспечивается в случае, если длина кратна размеру физического кластера диска (512).
Реальный размер файла не кратен значению при открытии файла.
операця чтения с нетипизированных файлов:
blockread(ифп, BUF, count [, result]);
blockwrite(ифп, BUF, count [, result]);
BUF – буфер с данными (куда писать или откуда читать) – переменная.
count – количество блоков, объёмом указанным в reset.
Размер переменной буфера должен быть не меньше, чем произведение размера элементаа (указано в reset) на количество блоков (count).
result – для blockread указывает на объём прочитанных данных, а для blockwrite – это объём записанных данных. (Если было прочитано 150 байт данных, а надо было 4 блока по 200 байт, то result будет 1)
6. Особенности работы с типами в TP. Явные преобразования типов.
Приведение типов позволяет рассматривать одну и ту же величину в памяти ЭВМ как принадлежащую разным типам. Для этого используется конструкция:
Имя_Типа(переменная или значение)
Например:
Integer(‘Z’); - представляет собой значение кода символа в двухбайтном представлении целого числа
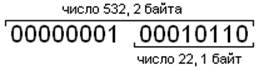 Byte(534); -
даст значение 22, поскольку целое число 534 имеет тип Word изанимает
2 байта, а тип byte –
один байт, и в процессе приведения старший байт будет отброшен.
Byte(534); -
даст значение 22, поскольку целое число 534 имеет тип Word изанимает
2 байта, а тип byte –
один байт, и в процессе приведения старший байт будет отброшен.
7. Эквивалентность типов.
Два типа эквивалентны (идентичны), если выполняется одно из условий:
· Оба типа представляют собой одно и то же имя типа.
· Один из типов описан с использованием другого типа с помощью равенства или последовательности равенств. Например:
type
T1 = integer;
T2 = T1;
T3 = T2;
8. Совместимость типов.
Два типа совместимы, если выполняется одно из условий:
· Они эквивалентны.
· Один тип интервальный, а другой – его базовый.
· Оба типа интервальные с общим базовым.
· Один тип строковый, а другой символьный.
10. Типизированные константы.
Тип констант определяется ближайшим типом по присвоенному значению. Типизированным константам можно присваивать другие значения в теле
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.




