Отношения между компонентами-сущностями
Большую часть отношений между компонентами-сущностями мы рассмотрели в этой главе, в разделе "Схема абстрактной персистентности". Достаточно повторить основную идею: следует использовать компоненты-сущности для крупных данных и избегать их применения для мелких данных.
Определение компонентов-сущностей в приложениях масштаба предприятия
Вообще говоря, для идентификации компонентов-сущностей, которые нужны в системе, следует брать за основу классы-сущности, определенные на этапе анализа.
Возвращаясь к примеру электронной банковской системы HomeDirect, можно вспомнить, что в каждом из прецедентов мы определили один или несколько классов-сущностей. Например, в прецеденте "Перевод денег" были задействованы, среди прочих, классы Accountи CustomerProfile. Оба они являются хорошими "кандидатами" в компоненты-сущности, так как изображают довольно крупные данные и обособлены от других.
Конечно, у нас был еще класс Profile(профиль), содержащий имя пользователя и идентификатор клиента. Имеет ли смысл создавать компонент-сущность для каждого профиля? Хотя это технически выполнимо, но нежелательно по двум причинам. Во-первых, с каждым компонентом EJB сопряжены дополнительные затраты ресурсов и времени, и поэтому целесообразно не увеличивать их количество. Во-вторых, компоненты-сущности обычно представляют (логическую) запись в базе данных, и разделение записи профиля на несколько компонентов даст нежелательные результаты.
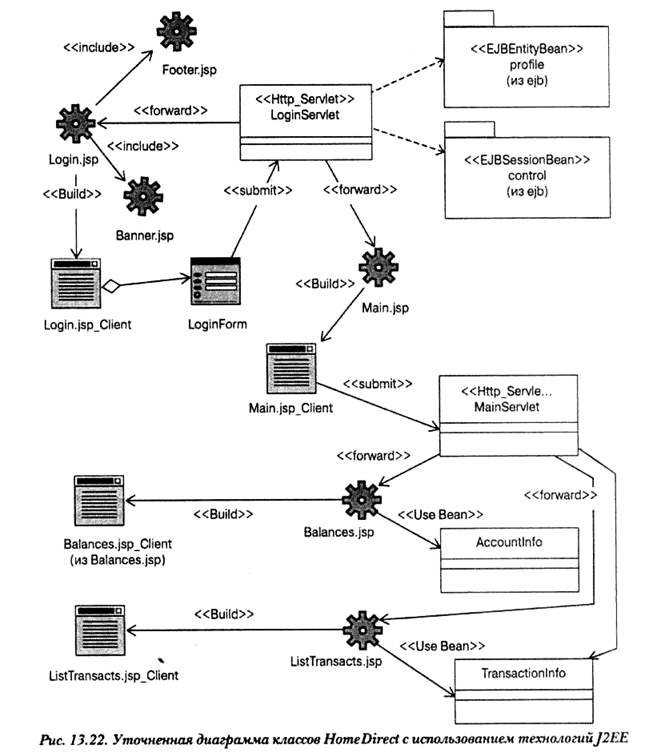
На рис. 13.22 изображена часть уточненной диаграммы классов системы HomeDirect, переработанная с использованием всех технологий, которые мы рассмотрели ранее.
Заметьте, что клиент не обращается к компонентам-сущностям непосредственно. Доступ производится через сервлет (при входе в систему) или через сеансовый компонент, играющий роль контроллера сеанса (в большинстве других прецедентов). Это общепринятый шаблон. Такую методику можно также назвать "обертыванием" компонентов-сущностей в сеансовый компонент. Она позволяет уменьшить количество требуемых сетевых вызовов и достичь более четкого разделения обязанностей. Некоторые взаимодействия компонента-сущности не показаны на этой диаграмме из-за недостатка места.
Наряду с описанным подходом можно использовать и другую методику, которая заключается в том, что информация компонента-сущности помещается в компонент Java-Beans, который возвращается при обращении к нему. Это также дает сокращение числа сетевых вызовов. К информации в JavaBeans можно обращаться локально и даже изменять ее, а затем по заранее установленному плану обновлять исходный компонент-сущность.
Не имеет ли смысл заключать в компоненты-сущности каждый элемент данных, который только может понадобиться для приложения, чтобы получить их общее объектно-ориентированное представление? Оказывается, нет. Вспомните о затратах, с которыми связано существование компонентов-сущностей. В некоторых ситуациях может быть целесообразно использовать вместо них компоненты JavaBeans, в которые непосредственно помещается код доступа к базе данных. Такой подход наиболее приемлем, если требуется только чи-тать данные и не нужно проводить транзакции или обновлять информацию. Самый большой недостаток этого подхода — нарушение стратегии J2EE, которая предполагает архитектуру, основанную на компонентах-сущностях. Поэтому может быть целесообразно начать с применения EJB и рассматривать упрощенную схему без компонентов-сущностей как альтернативный вариант реализации, к которому можно перейти при необходимости.
![]()
![]()
![]()
![]() Многоуровневое представление
Многоуровневое представление
Как мы уже говорили в главе 6, многоуровневое представление предполагает логическую организацию пакетов и подсистем для разбиения системы по функциональному признаку. В практическом исследовании мы разобьем проект J2EE на уровни, руководствуясь рекомендациями RUP. В частности, в RUP предлагается схема разбиения на уровни по повторному использованию. Выделяются следующие уровни.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.