












Министерство образования и науки Российской Федерации
Государственное образовательное учреждение
высшего профессионального образования
«Комсомольский-на-Амуре государственный технический университет»
Лабораторная работа № 2
по курсу «Теория языков программирования и методы трансляции»
Студенты группы 4ВC-1 Казаков М.Ю.
Неделько Н.Н.
Преподаватель Петрова А.Н.
2007
Тема:
Лексический анализ.
Цель работы:
Изучить работу и методы построения лексического анализатора.
Задание:
Написать программу лексического анализатора для языка C.
Первый этап построения лексического анализатора
Выделим во входном языке шесть классов лексем и определим код каждого класса.
1) 10 – ключевые слова;
2) 20 – идентификаторы;
3) 30 – разделители;
4) 40 – числовые константы;
5) 50 – символьные константы;
6) 60 – строковые константы.
Второй этап построения лексического анализатора
Построим для каждого класса лексем автоматную грамматику.
1) для ключевых слов G1 = <N1, T1, P1, S1>, где
N1 = {D, L, T, S}, T1 = {A, B, …, Y, Z, a, b, …, y, z, _, 0, 1, … , 8, 9}, S1 = {S},
P1 =
{
S → L | LT
T → LT | DT | L | D
L → A | B | … | Y | Z | a | b | … | y | z | _
D → 0 | 1 | … | 8 | 9
}
2) для идентификаторов грамматика будет точно такой же, как и для ключевых слов.
3) для разделителей G2 = <N2, T2, P2, S2>, где
N2 = {S, A, I, P, M, E}, T2 = {+, -, <, >, =, !, /, *, &, |, (, ), {, }, [, ], %, ., ,, ;}, S2 = {S},
P2 =
{
S → + | +P | - | -M | < | < E| > | >E | = | =E | ! | !E | / | * | &A | |I | ( | ) | { | } | [ | ] | % |.| , | ;
A → &
I → |
P → +
M → E → =
}
4) для числовых констант G3 = <N3, T3, P3, S3>, где
N3 = {D, S, T}, T3 = {0, 1, …, 8, 9, ‘.’}, S3 = {S},
P3 =
{
S → T
T → DT | .T | D | .
D → 0 | 1 | … | 8 | 9
}
5) для символьных констант G4 = <N4, T4, P4, S4>, где
N4 = {D, S, T, L, C}, T4 = {A, B, … , y, z, _, 0, … , 9, ”, ’, \, !, #, %, ^, &, *, (, ), +, -, =, |, :, ;, ,,.} S4 = {S},
P4 =
{
S → ‘T
T → \D | LT | C
D → \C | nC | tC | ‘C | “C
L → A | … | z | _ | 0 | … | 9 | # | % | … | .
C → ‘
}
6) для строковых констант G5 = <N5, T5, P5, S5>, где
N5 = {D, S, T, L}, T5 = {A, B, … , y, z, _, 0, … , 9, ”, ’, \, !, #, $, %, ^, &, *, (, ), +, -, =, |, :, ;, ,,.}, S5 = {S},
P5 =
{
S → “T
T → \D | LT | C
D → \T | nT | tT | ‘T | “T
L → A | … | z | _ | 0 | … | 9 | # | % | … | .
C → “
}
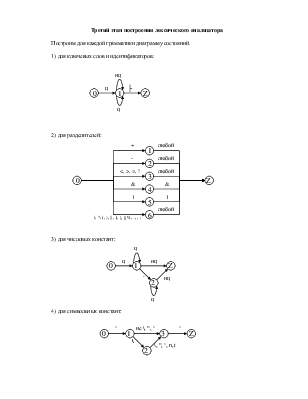
Третий этап построения лексического анализатора
Построим для каждой грамматики диаграмму состояний.
1) для ключевых слов и идентификаторов:
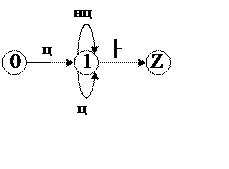 |
2) для разделителей:
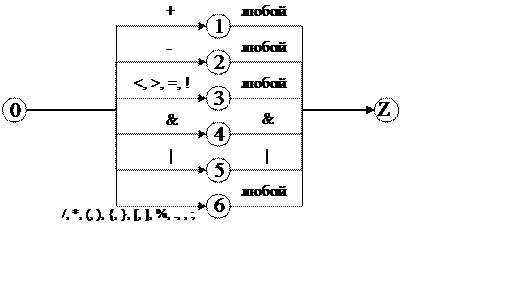 |
3) для числовых констант:
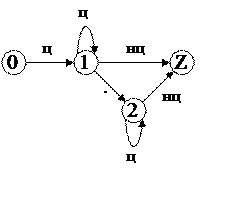 |
4) для символьных констант:
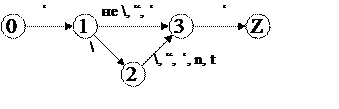 |
5) для строковых констант:
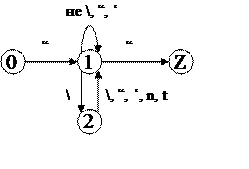 |
Четвертый этап построения лексического анализатора
Запрограммируем семантические подпрограммы и распознаватель.
//--------------------------------------------------------------------------#include <vcl.h>
#pragma hdrstop
#include "Unit1.h"
#include <string.h>
//--------------------------------------------------------------------------#pragma package(smart_init)
#pragma resource "*.dfm"
#define LETTER 10
#define SEPARATOR 30
#define DIGIT 40
#define SYMBOL 50
#define STR 60
#define SPACE 70
#define ADDITIONAL 80
#define ERROR -1
#define END -10
#define NEWLINE -20
TForm1 *Form1;
//--------------------------------------------------------------------------__fastcall TForm1::TForm1(TComponent* Owner)
: TForm(Owner)
{
}
//--------------------------------------------------------------------------char *str, buffer[100];
AnsiString des;
AnsiString msg;
int curlex, NumLine;
int countKW, countId, countSep, countSym, countStr, countDig;
char **KW, **Id=0, **Sep, **Sym, **Str, **Dig;
char *AllKeyWords[13] = {"break", "char", "continue", "else", "float", "for",
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.