Printf(“P1:%f,M1”) cout<<” \nP1:”<<M1
Printf(“P2:%f,M2”) cout<<”\nP2:”<<M2
Статистика (5(2).срр)
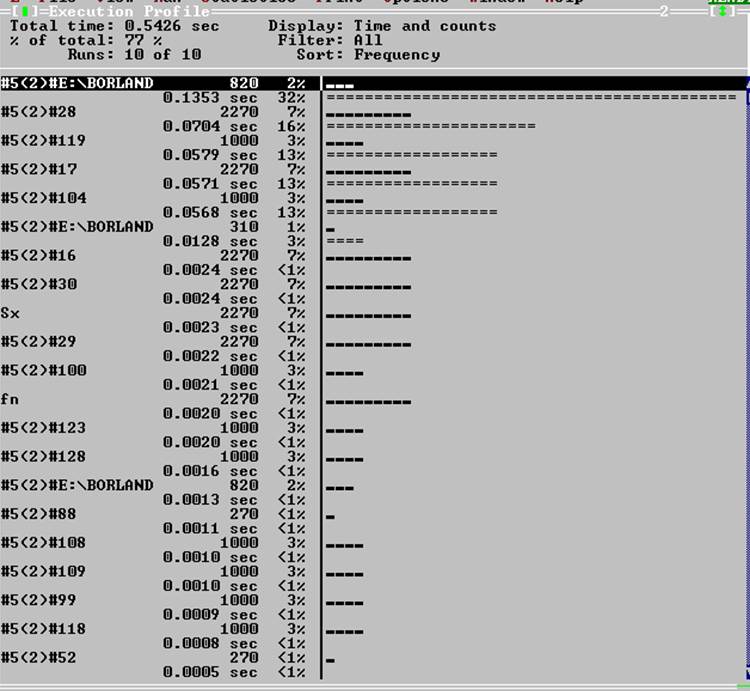
Рис. 4
Окно Файлы

Рис. 5
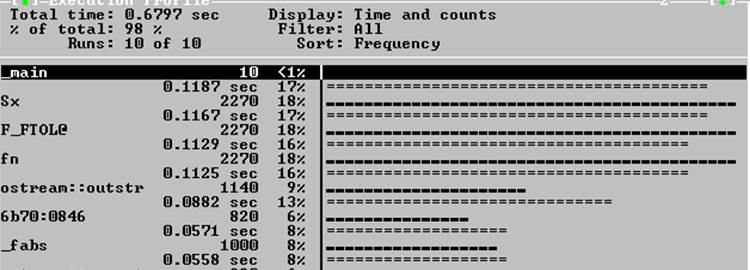
Рис. 6
Данные
#5(2)#E:\Borland функция cout в библиотеке iostream.h
#5(2)#28 i=int((x-A)/h)
#5(2)#119 yy[i]=fn(xx[i])
#5(2)#17 выход из функции
#5(2)#104 zz[i]=Sx(xx[i])
#5(2)#E:\Borland функция cout в библиотеке iostream.h
Время выполнения программы сократилось на 0.1978 сек. относительно первоначальных данных (рис. 4). На рисунке 6 отображена статистика по функциям. Видно, что неудовлетворительно работают следующие функции:
_main
ostream::outstr
6b70:0846
_fabs
По результатам первого изменения видно, что основное время программы тратится на вывод информации. Тем не менее, исходя из данных окна Файлы (рис. 2, рис. 5) количество записей и время увеличились, но сократился объем информации. Продолжим работать с операторами вывода. В качестве вывода сообщений будем использовать оператор cprintf()
Второе изменение
Исходные строки Преобразованные строки
cout<<” Interpoliacionnaia tablica\n” cprintf(“Interpoliacionnaia tablica\n”)
cout<<” \t x f(x) s(x)\n” cprintf(“\t x f(x) s(x)\n”)
cout<<” "\t\n"<<Xi[i]<<Yi[i]<<Sx(Xi[i])” cprintf(“\t% .3f%12f%12f\n", Xi[i], Yi[i], Sx(Xi[i]))
cout<<” \nP1:”<<M1 cprintf(“P1:%f,M1”)
cout<<”\nP2:”<<M2 cprintf(“P2:%f,M2”)
Статистика 5(3).cpp
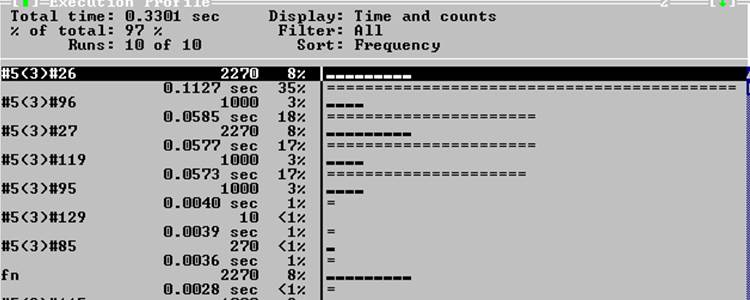
Данные
#5(3)#26 i=int((x-A)/h)
#5(3)#96 yy[i]=fn(xx[i])
#5(3)#27 return
#5(3)#119 zz[i]=Sx(xx[i])
#5(3)#129 выход из программы
Время выполнения программы сократилось с 0.5426 до 0.3301 относительно предыдущего изменения. Так как в данном случае не используется стандартный поток вывода, то окно Файлы не будет содержать записей. По данным статистики видно, что основное время работы программы тратится на строку #5(3)#26 (входит в функцию Sx()). Так же работает и строчка #5(3)#96. В строке #5(3)#27 оператор return возвращает значение многочлена. Попробуем изменить функцию Sx() и Sshx(). Для начала определим переменную i глобально; затем изменим вычисление многочленов в этих функциях.
Третье изменение
Исходные строки Преобразованные строки
int i=int((x-A)/h) int i,j;
i=int((x-A)/h);
return j=x-Xi[i];
Ai[i]+Bi[i]*(x-Xi[i])+ return Ai[i]+Bi[i]*j+Ci[i]*j*j+Di[i]*j*j*j
+Ci[i]*(x-Xi[i])*(x-Xi[i])+
+Di[i]*(x-Xi[i])*(x-Xi[i])*(x-Xi[i]);
return Bi[i]+2*Ci[i]*(x-Xi[i])+ return Bi[i]+2*Ci[i]*j+3*Di[i]*j*j
+3*Di[i]*(x-Xi[i])*(x-Xi[i])
Статистика 5(4).cpp
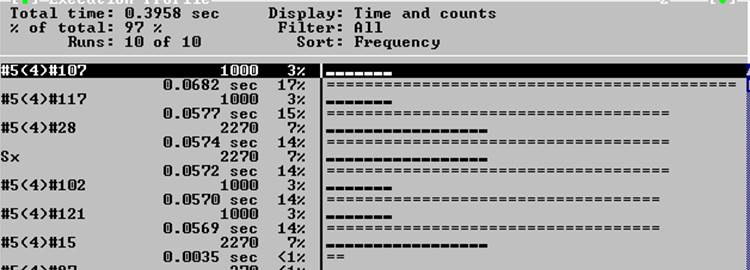
Данные
#5(4)#107 if()
#5(4)#117 yy[i]=fn(xx[i])
#5(4)#28 return
Sx() функция
#5(4)#102 zz[i]=Sx(xx[i])
#5(4)#121 zz[i]=Sx(xx[i])
Время выполнения программы увеличилось с 0.3301 до 0.3958 относительно предыдущего изменения.
Программное время уменьшилось за счет меньшего количества обращений к внешним библиотечным функциям. Функция fn() – максимально проста. Оператор return не представляется возможным изменить либо заменить более продуктивными. Функция Sx() была оптимизирована.
Выводы:
Профилирование программ в системе Turbo Profiler с целью повышения их быстродействия – это динамичный интерактивный процесс. Последовательно собирая статистику, анализируя данные о процессе выполнения, были предприняты существенные преобразования исходного текста, пока не был получен приемлемый, с нашей точки зрения, результат, хотя последнее изменение не является оптимальным, т.к. был получен худший результат относительно предыдущего изменения. Это подтверждается следующим: время выполнения программы в целом сократилось на 0,3446 сек., что быстрее изначального. В результате программный модуль стал менее требователен к ресурсам ПЭВМ, а точнее: к времени выполнения, а результаты выполнения не претерпели изменений.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.