



Выполнить сортировку данных, представленных в виде одномерного массива.
На начальном шаге алгоритма сортировки исходные данные разбиваются на несколько групп, каждая из которых сортируется независимо от остальных. После окончания сортировки происходит обмен между соседними компьютерами своими минимальными и максимальными значениями, исключение составляют только первый (нулевой) и последний компьютеры. Остановка происходит в том случае, когда не удается сделать ни одного обмена.
int main()
{
{Чтение исходных данных с их рассылка компьютером с номером size-1}
while (выполняется условие продолжения)
{
{Сделать сортировку своей группы данных}
{Послать соседям минимальное и максимальное значения}
{Принять от соседей посланные ими значения}
if (условие обмена выполняется)
{Выполнить обмен}
if (это первый компьютер)
{Получить необходимую информацию от других и принять решение о продолжении сортировки}
else
{Послать первому компьютеру информацию о продолжении сортировки}
}
{Освобождение всей занимаемой памяти}
}
Внутри каждой группы происходит сортировка методом «пузырька».
while (была произведена хотя бы одна перестановка)
{
for( i=0; i<d-1; i++)
if (текущий элемент > последующего)
{произвести перестановку}
}
Результаты
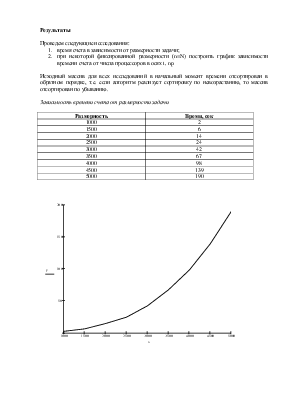
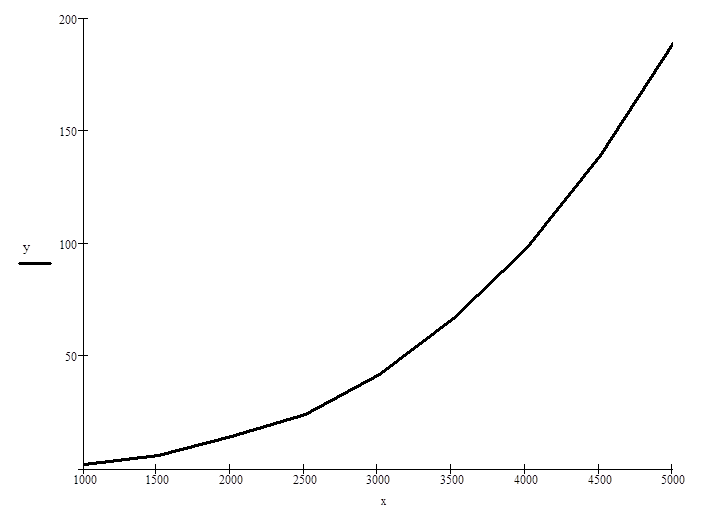
Проведем следующие исследования:
1. время счета в зависимости от размерности задачи;
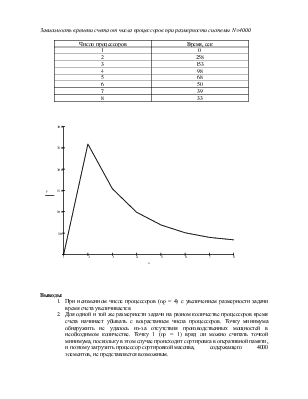
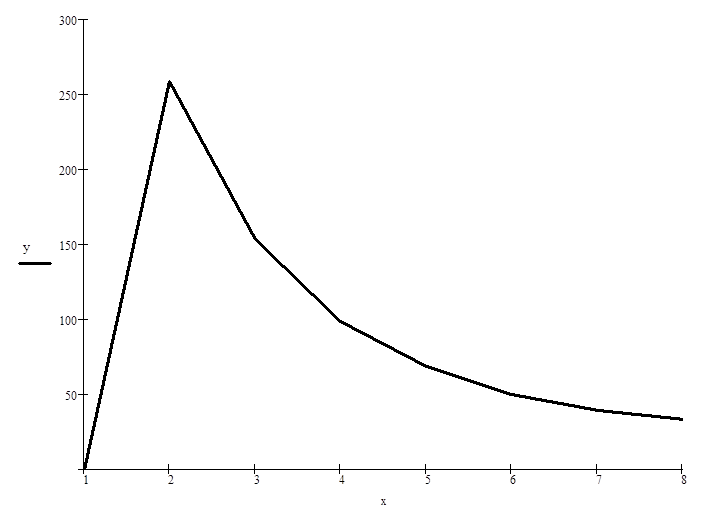
2. при некоторой фиксированной размерности (n=N) построить график зависимости времени счета от числа процессоров в осях t, np.
Исходный массив для всех исследований в начальный момент времени отсортирован в обратном порядке, т.е. если алгоритм реализует сортировку по невозрастанию, то массив отсортирован по убыванию.
Размерность |
Время, сек |
|
1000 |
2 |
|
1500 |
6 |
|
2000 |
14 |
|
2500 |
24 |
|
3000 |
42 |
|
3500 |
67 |
|
4000 |
98 |
|
4500 |
139 |
|
5000 |
190 |
|
Число процессоров |
Время, сек |
|
1 |
0 |
|
2 |
258 |
|
3 |
153 |
|
4 |
98 |
|
5 |
68 |
|
6 |
50 |
|
7 |
39 |
|
8 |
33 |
Выводы:
1. При неизменном числе процессоров (np = 4) с увеличением размерности задачи время счета увеличивается.
2. Для одной и той же размерности задачи на разном количестве процессоров время счета начинает убывать с возрастанием числа процессоров. Точку минимума обнаружить не удалось из-за отсутствия производственных мощностей в необходимом количестве. Точку 1 (np = 1) вряд ли можно считать точкой минимума, поскольку в этом случае происходит сортировка в оперативной памяти, и поэтому загрузить процессор сортировкой массива, содержащего 4000 элементов, не представляется возможным.
#include <mpi.h>
#include <stdio.h>
#include <time.h>
#include <math.h>
#include <float.h>
#define ND 1
double *A;
double max_loc=1e+30,min_loc=-1e+30;
int n,m,L;
time_t starttime,finishtime;
void sort (double *array, int d)
{
int flag=1,i;
double temp;
while (flag==1)
{
flag=0;
for(i=0;i<d-1;i++)
{
if (array[i]>array[i+1])
{
temp=array[i];
array[i]=array[i+1];
array[i+1]=temp;
flag=1;
}
}//end of for
} // end of while
} //end of sort
int main( int argc, char *argv[])
{
int tag=11,rank,size,start;
MPI_Status st;
MPI_Comm ring;
int dims[ND],per[ND],reord=0,prev,next;
int i,j,d;
FILE *fp;
int flag1_ext=1;
int flag2_int=1;
int recv_flag=0;
MPI_Init(&argc,&argv);
MPI_Comm_rank(MPI_COMM_WORLD,&rank);
MPI_Comm_size(MPI_COMM_WORLD,&size);
per[0]=1;
dims[0]=0;
MPI_Dims_create(size,ND,dims);
MPI_Cart_create(MPI_COMM_WORLD,ND,dims,per,reord,&ring);
MPI_Cart_shift(ring,0,-1,&prev,&next);
if (rank == (size-1))
{
fp=fopen("input.txt","rt");
fscanf(fp,"%d",&n);
for (i=0;i<size-1;i++)
MPI_Send(&n,1,MPI_INT,i,tag,ring);
L=n/size+1;
start=size-(L*size-n);
A=(double*)malloc(L*sizeof(double));
for(i=0;i<start;i++)
{
for(j=0;j<L;j++)
fscanf(fp,"%lf",&A[j]);
if (i!=size-1)
MPI_Send(A,L,MPI_DOUBLE,i,tag,ring);
}
for(i=start;i<size;i++)
{
for (j=0;j<L-1;j++)
fscanf(fp,"%lf",&A[j]);
if (i!=size-1)
MPI_Send(A,L-1,MPI_DOUBLE,i,tag,ring);
}
fclose(fp);
} //end of if block
else
{
MPI_Recv(&n,1,MPI_INT,size-1,tag,ring,&st);
L=n/size+1;
start=size-(L*size-n);
A=(double*)malloc(L*sizeof(double));
if(rank<start)
MPI_Recv(A,L,MPI_DOUBLE,size-1,tag,ring,&st);
else
MPI_Recv(A,L-1,MPI_DOUBLE,size-1,tag,ring,&st);
if(rank==0)
starttime=time(NULL);
} //end of else block
d=(rank<start)?L:L-1;
while (flag1_ext)
{
if (flag2_int != 0) sort(A,d);
flag2_int=0;
if (rank!=0)
{
MPI_Send(&A[0],1,MPI_DOUBLE,rank-1,tag,ring);
MPI_Recv(&min_loc,1,MPI_DOUBLE,rank-1,tag,ring,&st);
}
if (rank!=size-1)
{
MPI_Send(&A[d-1],1,MPI_DOUBLE,rank+1,tag,ring);
MPI_Recv(&max_loc,1,MPI_DOUBLE,rank+1,tag,ring,&st);
}
if (max_loc < A[d-1] )
{
A[d-1]=max_loc;
flag2_int=1;
}
if (min_loc > A[0])
{
A[0]=min_loc;
flag2_int=1;
}
if (rank==0)
{
recv_flag=0;
flag1_ext=flag2_int;
for(i=1;i<size;i++)
{
MPI_Recv(&recv_flag,1,MPI_INT,i,tag,ring,&st);
flag1_ext=(flag1_ext || recv_flag);
}
for(i=1;i<size;i++)
MPI_Send(&flag1_ext,1,MPI_INT,i,tag,ring);
}
else
{
MPI_Send(&flag2_int,1,MPI_INT,0,tag,ring);
MPI_Recv(&flag1_ext,1,MPI_INT,0,tag,ring,&st);
}
}//end of while
if (rank==0)
{
finishtime=time(NULL);
fp=fopen("output.txt","wt");
fprintf(fp,"%d",n);
for(i=0;i<d;i++)
fprintf(fp,"\nRank=0 %lf",A[i]);
for(i=1;i<size;i++)
{
d=(i<start)?L:L-1;
MPI_Recv(A,d,MPI_DOUBLE,i,tag,ring,&st);
for(j=0;j<d;j++)
fprintf(fp,"\nRank=%d %lf",i,A[j]);
}
fprintf(fp,"\nВремя в секундах: %f",difftime(finishtime,starttime));
fclose(fp);
}
else
MPI_Send(A,d,MPI_DOUBLE,0,tag,ring);
free(A); // free memory
MPI_Finalize();
return 0;
}//end of main
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.