Лабораторная работа №3
по дисциплине «Методы моделирования»
Вариант 4
Факультет: ПМИ
Группа: ПМ-83
Студенты: Большакова А.
Журавлев В.
Миркин Е.
Преподаватели: Тишковская С.В.
Тимофеев В.С.
г. Новосибирск 2000г.
1. Задание
Найти моделирующее выражение и написать алгоритм моделирования для случайной величины x, имеющей заданную плотность распределения f(x):
1) по методу обратной функции (далее обозначаем МОФ)
f(x)=1/2*|sin x|, xÎ[-p/2,p/2]
2) по МОФ при немонотонной j(a)
f(x)=C*(1+21/3x), C=1/(1+2–2/3), xÎ[0,1]
3) с использованием порядковых статистик
f(x)= 6/5*(x2-x+1), xÎ[0,1]
4) f(x)=C/(1+ex), C=1/ ln 2, xÎ[0,µ]
5) по методу суперпозиции
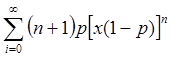
f(x)=
xÎ[0,1], 0<p<1
6) по методу исключения
f(x)=3/4*(1+x2), x Î[0,1]
2. Постановка задачи
Все методы моделирования сводится к преобразованию вида x=j(a1, …, an), где ai , i=1,…,n, независимые реализации равномерно распределенных псевдослучайных величин на отрезке [0,1].
1. Метод обратной функции (МОФ):
x=F–1(a), где F(x) – функция распределения случайной величины x.
Для немонотонных преобразований j(a)=F–1(a) моделирующее выражение можно строить на основе следующего утверждения.
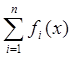 Утверждение.
Утверждение.
Пусть fn(x)= ,pi=ò-µµ fi(x)dx, Fi(x)= ò-µx fi(t)dt,
a0=0, ai=åik=2 pk, где fi(x)>=0, i=1,…,n.
Тогда случайная величина x=F–1i(a–ai–1) при ai–1<=a<ai имеет плотность распределения fn(x).
2. Метод с использованием порядковых статистик:
Пусть f(x)=nCk-1n-1xk-1(1–x)n-k, xÎ(0,1), где n и k – некоторые натуральные числа. Тогда x – это k-я порядковая статистика для выборки a1,…, an, aiÎRav(0,1). Моделирование случайной величины x сводится к непосредственному моделированию a1,…, an, с последующим их упорядочиванием , так что x=a(k).
3. Метод суперпозиции:
Есть маргинальное распределение fx(x) и надо построить моделирующее выражение для величины xÎ fx(x,y). Для этого находятся маргинальная плотность распределения fh(y), совместная плотность распределения f(x,y) и условная плотность распределения fx(x | y=h).
f(x,y)= ![]() fx(x,y),
fx(x,y),
fh(y)= 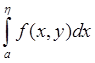 , xÎ[a,b]
, xÎ[a,b]
fx(x | y=h) = 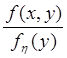
Тогда нахождение случайной велины происходит по следующему алгоритму:
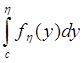 =Ф(h), h=Ф-1(a1), xÎ[c,d]
=Ф(h), h=Ф-1(a1), xÎ[c,d]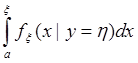 =F(x,h), x=F-1(a2,h), yÎ[a,b]
=F(x,h), x=F-1(a2,h), yÎ[a,b]4. Метод исключения:
Для моделирования случайной величины x с плотностью распределения f(x), xÎ[a,b], выполняются следующие действия:
иначе x=x0.
М=max f(x), xÎ[a,b].
3. Моделирующие выражения
1) x= arccos 2a, если aÎ[0,1/2) или arcos 2*(1-a), если aÎ[1/2,1];
2) x= a/C, aÎ[0,C)
= (a*22/3/C)1/2, aÎ[C,1],
C=1/(1+2-2/3) ;
3) x= a(1), n=3, если aÎ[0,2/5) или a(2), n=2, если aÎ[2/5,1]:
4) M=1/ln 4;
5) величина h – дискретна, поэтому используется модель моделирования дискретной величины, а не непрерывной.
hÎ P{h=n}=p(1-p)n.
x=a21 / (h+1)
6) M=3/2.
4. Проверка выборки.
Для того, чтобы проверить принадлежит ли выборка заданному распредеелению, используем критерий c2 – Пирсона. Определим 2 гипотезы:
H0 : F=F(x)
H1 : F¹F(x), где F(x) – функция распределения заданной плотности.
Тогда для проверки строим статистику hi и проверяем, если она меньше, чем квантиль распределения c2 (L–1, a), то гипотеза Н0 справедлива и выборка принадлежит заданному распределению, иначе надо отвергнуть гипотезу Н1.
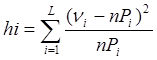 ,
,
где L – количество интервалов заданной области значений,
![]() - частота, равная количеству элементов,
попавших в i-й интервал,
- частота, равная количеству элементов,
попавших в i-й интервал,
Pi= F(di+1) – F(di), где F(x) – заданное распределение,
a=PH0{hi>![]() } – вероятность отвергнуть данные при
условии, что они верны (a – ошибка 1-го рода),
} – вероятность отвергнуть данные при
условии, что они верны (a – ошибка 1-го рода),
n – объем выборки.
5. Тесты
Построены графики зависимостей статистик hi и квантилей ss от количества интервалов L, на которые разбиты области значений случайных величин, где LÎ[2,29] и a=0.5.
Тест 1: для разных объемов
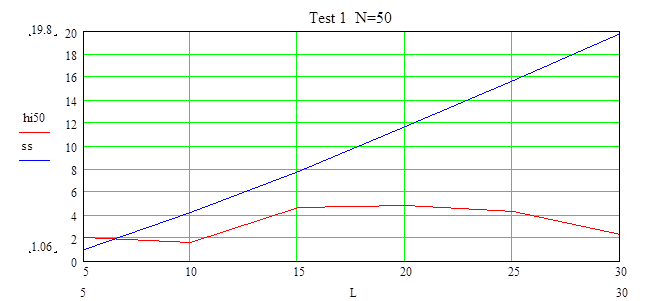
На графике видно, что выборка принадлежит заданному распределению с уровнем доверия a=0.9 при достаточно большом числе интервалов.
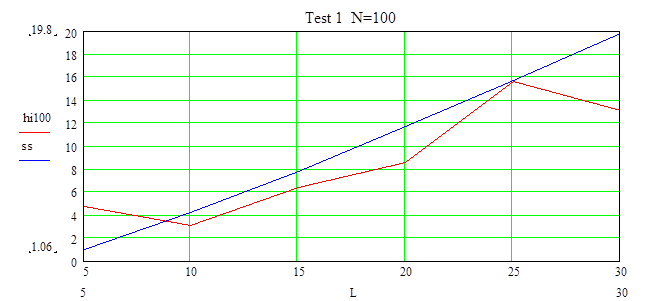
На этом тесте видно, что при этом объема надо выбирать число интервалов больше 10, тогда гипотеза принимается с уровнем доверия a=0.9.
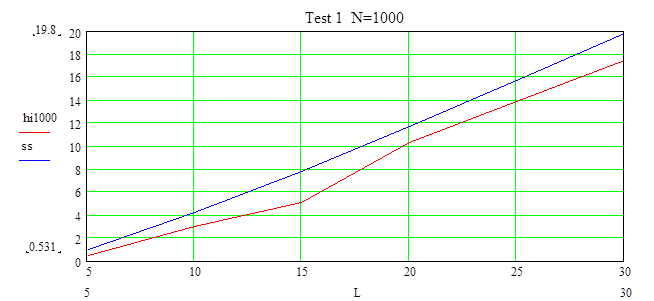
Данный объем достаточен для принятия гипотезы на любом числе интервалов при уровне доверия a=0.9.
Тест 2. для разных объемов выборки
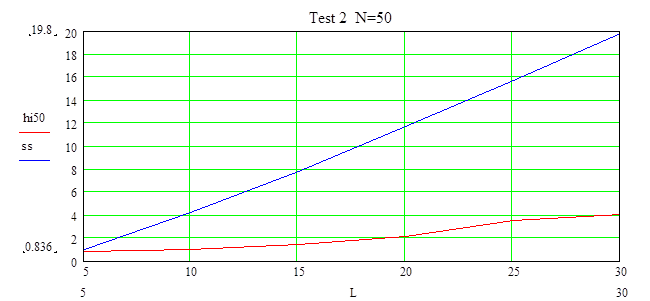
На графике видно, что при всех значениях L гипотезу о принадлежности к заданному распределению надо принять. Причем выборка распределена достаточно хорошо, т.е с уровнем доверия a>0.9.
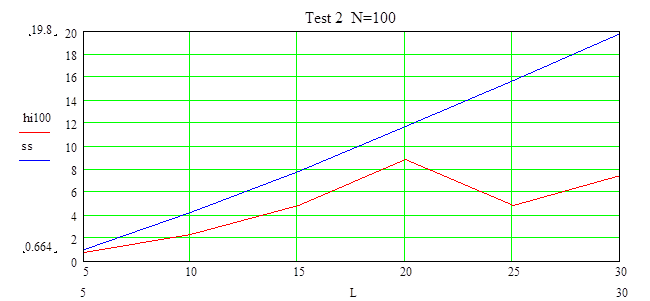
При данной объеме N=100 выборка принадлежит к заданному распределению при a=0.9 и при увеличении значений L уровень доверия может быть выше.
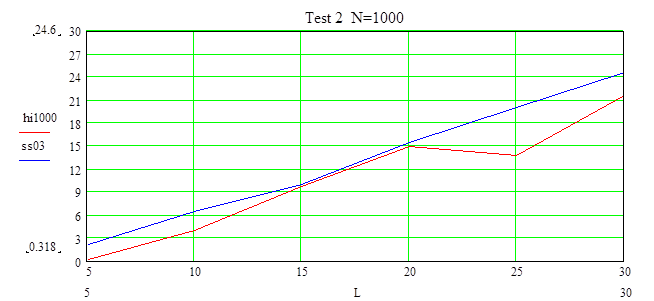
При объема N=1000 выборка принадлежит распределению при любом числе интервалов, но уровень доверия почти не может быть увеличен (только при L от 25 до30).
Тест 3. для разных объемов выборки
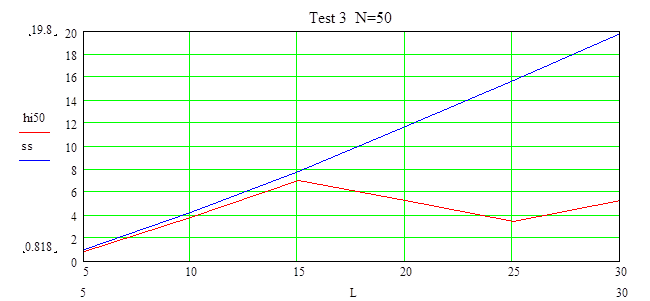
На числе интервалов от 5 до 15 выборка принадлежит распределению с уровнем доверия a=0.9, но при увеличении числа L уровень доверия повышается.
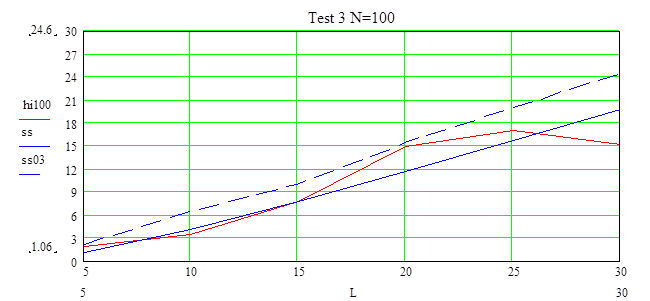
На этом графике видно, что при уровне доверия a=0.9 выборка принадлежит распределению только при L=10 и L=30, а при уменьшении уровня доверия до a=0.7 выборка полностью принадлежит заданному распределению на всех значениях числа интервалов, но это уже не очень хорошее значение уровня доверия.
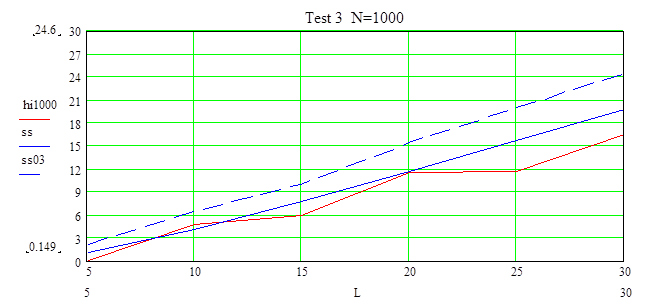
Этот график показывает принятие гипотезы о заданном распределении и при уровне доверия a=0.7 и при a=0.9 (на больших значениях L).
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.

