//reading of matrix
if (rank==0)
{
F=fopen("input.txt","rt");
fscanf(F,"%d",&M);
MPI_Bcast(&M,1,MPI_INT,0,MPI_COMM_WORLD);
N = M / size;
W = (float*)malloc((M+1)*sizeof(float));
A = (float**)malloc(N*sizeof(float*));
for (i=0; i<N; i++)
A[i]=(float*)malloc((M+1)*sizeof(float));
for (i=0; i<N; i++)
{
for (j=0; j<M+1; j++)
fscanf(F,"%f",&A[i][j]);
for (k=1; k<size; k++)
{
for (j=0; j<M+1; j++)
fscanf(F,"%f",&W[j]);
MPI_Send(W,M+1,MPI_FLOAT,k,10,MPI_COMM_WORLD);
}
}
//printf("0 sent line %d to %d\n",i,i/N);
fclose(F);
//printf("matrix sent succ.\n");
//getchar();
}
else
{
MPI_Bcast(&M,1,MPI_INT,0,MPI_COMM_WORLD);
N = M / size;
W = (float*)malloc((M+1)*sizeof(float));
A = (float**)malloc(N*sizeof(float*));
for (i=0; i<N; i++)
A[i]=(float*)malloc((M+1)*sizeof(float));
for (i=0; i<N; i++)
{
MPI_Recv(W,M+1,MPI_FLOAT,0,10,MPI_COMM_WORLD,&st);
//printf("%d got line %d from 0\n",rank,i);
for (j=0; j<M+1; j++)
A[i][j]=W[j];
}
//printf("matrix gotten succ.\n");
}
// Direct Gauss moving
if (rank==0) gettimeofday(&t1,(struct timezone *)0);
d=0;
for (k=0; k<N; k++)
{
for (l=0; l<rank; l++)
{
//if (rank!=0) printf("rank = %d ; is to receive from %d\n",rank,l);
MPI_Recv(W,M+1,MPI_FLOAT,l,11,MPI_COMM_WORLD,&st);
//printf("rank = %d ; gotten line from %d\n",rank,l);
//scanf("%d",&z);
for (i=k; i<N; i++)
{
for (j=d+1; j<M+1; j++)
A[i][j]=A[i][j]-W[j]*A[i][d];
A[i][d]=0;
}
d++;
}
if (A[k][d]==0)
{
printf("Error!\n");
break;
}
for (j=d+1; j<M+1; j++)
A[k][j]=A[k][j]/A[k][d];
A[k][d]=1;
for (j=0; j<size; j++)
if ((j!=rank) && ((j>rank)||(k<(N-1))))
{
//printf("rank = %d ; is to send to %d\n",rank,j);
MPI_Send(A[k],M+1,MPI_FLOAT,j,11,MPI_COMM_WORLD);
//printf("rank = %d ; sent line to %d\n",rank,j);
//scanf("%d",&z);
}
//Preobrazuem svoi stroki
for (i=k+1; i<N; i++)
{
for (j=d+1; j<M+1; j++)
A[i][j]=A[i][j]-A[k][j]*A[i][d];
A[i][d]=0;
}
d++;
if (k<N-1)
{
for (l=rank+1; l<size; l++)
{
//if (rank!=0) printf("rank = %d ; is to receive from %d\n",rank,l);
MPI_Recv(W,M+1,MPI_FLOAT,l,11,MPI_COMM_WORLD,&st);
//printf("rank = %d ; gotten line from %d\n",rank,l);
for (i=k+1; i<N; i++)
{
for (j=d+1; j<M+1; j++)
A[i][j]=A[i][j]-W[j]*A[i][d];
A[i][d]=0;
}
d++;
}
}
}
//Indirect Gauss moving
for (k=N-1; k>=0; k--)
{
if (rank==size-1) d=0;
else d=rank+1;
if ((rank!=size-1) || (k!=N-1))
MPI_Recv(W,M,MPI_FLOAT,d,5,MPI_COMM_WORLD,&st);
W[size*k+rank]=A[k][M];
for (i=M-1; i>size*k+rank; i--)
W[size*k+rank]=W[size*k+rank]-W[i]*A[k][i];
if (rank==0) d=3;
else d=rank-1;
if ((rank!=0) || (k>0))
MPI_Send(W,M,MPI_FLOAT,d,5,MPI_COMM_WORLD);
}
if (rank==0) gettimeofday(&t2,(struct timezone *)0);
// OUTPUT
if (rank==0)
{
F=fopen("output.txt","wt");
for(i=0; i<M; i++)
fprintf(F,"%f\n",W[i]);
fprintf(F,"Time = %ld msec",(t2.tv_sec-t1.tv_sec)*1000000+(t2.tv_usec-t1.tv_usec));
fclose(F);
}
MPI_Finalize();
return(0);
}
А) Тест на правильность работы алгоритмов
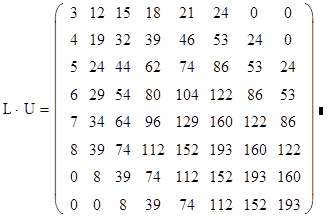
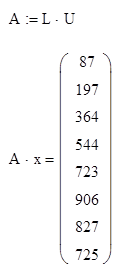
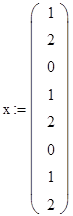
Обе программы верно решили заданное уравнение с высокой степенью точности. Таким образом, можно сделать вывод, что алгоритмы реализованы правильно.
Б) Тесты большой размерности
Для тестирования алгоритмов был использован генератор, генерирующий невырожденную матрицу для СЛАУ в заданном формате. Решением этой СЛАУ является вектор [1, 2, 3, … , N] , где N – размерность СЛАУ.
Оба алгоритма находили решение с одинаковой степенью точности (реализован один и тот же метод), но за разное время:
|
Размерность матрицы |
Время работы 1 алгоритма, мкс |
Время работы 2 алгоритма, мкс |
|
20 |
7913 |
15921 |
|
40 |
16386 |
32140 |
|
60 |
25077 |
51794 |
|
80 |
37325 |
74119 |
|
100 |
53786 |
98997 |
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.