LR-анализатор (англ. LRparser) — синтаксический анализатор для исходных кодов программ, написанных на некотором языке программирования, который читает входной поток слева (Left) направо и производит наиболее правую (Right) продукцию контекстно-свободной грамматики. Используется также термин LR(k)-анализатор, где k выражает количество непрочитанных символов предпросмотра во входном потоке, на основании которых принимаются решения при анализе.
Восходящий разбор (англ. Bottom-up
parsing) предназначен для
построения дерева разбора. Мы
можем представить себе этот процесс как "свертку" исходной строки ![]() к стартовому нетерминалу
грамматики. Каждый шаг свертки заключается в сопоставлении некоторой подстроки
к стартовому нетерминалу
грамматики. Каждый шаг свертки заключается в сопоставлении некоторой подстроки ![]() и правой части какого-то
правила грамматики, затем происходит замена этой подстроки на нетерминал,
являющийся левой частью правила. Восходящий разбор менее интуитивно понятный,
чем нисходящий, но зато позволяет разбирать больше грамматик.
и правой части какого-то
правила грамматики, затем происходит замена этой подстроки на нетерминал,
являющийся левой частью правила. Восходящий разбор менее интуитивно понятный,
чем нисходящий, но зато позволяет разбирать больше грамматик.
|
Определение: |
|
Пусть |
|
Определение: |
|
Пусть § § следует, что |
Говоря
неформально, мы делаем правостороннюю свёртку нашей строки в стартовый
нетерминал. Если по не более чем ![]() символам неразобранной
части строки мы можем однозначно определить, во что сворачивается хвост
выведенного правила, то грамматика будет LR(k).
символам неразобранной
части строки мы можем однозначно определить, во что сворачивается хвост
выведенного правила, то грамматика будет LR(k).
LR(k) означает, что:
§ входная цепочка обрабатывается слева направо (англ. left-to-right parse),
§ выполняется правый вывод (англ. rightmost derivation),
§
для
принятия решения используется не более ![]() символов цепочки (англ. k-token lookahead).
символов цепочки (англ. k-token lookahead).
Существенность
использования пополненной грамматики в определении LR(k)-грамматик
продемонстрируем на следующем конкретном примере. Действительно, если
грамматика использует ![]() в правых частях правил, то
свертка основы в
в правых частях правил, то
свертка основы в ![]() не может служить сигналом
приема входной цепочки. Свертка же в
не может служить сигналом
приема входной цепочки. Свертка же в ![]() в пополненной
грамматике служит таким сигналом, поскольку
в пополненной
грамматике служит таким сигналом, поскольку ![]() нигде, кроме начальной
сентенциальной формы, не встречается.
нигде, кроме начальной
сентенциальной формы, не встречается.
Существенность использования пополненной грамматики в определении LR(k)-грамматик продемонстрируем на следующем конкретном примере. Пусть пополненная грамматика имеет следующие правила:
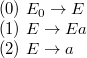
Если
игнорировать ![]() -е правило, то, не заглядывая в правый контекст основы
-е правило, то, не заглядывая в правый контекст основы ![]() , можно сказать, что она должна сворачиваться в
, можно сказать, что она должна сворачиваться в ![]() . Аналогично основа
. Аналогично основа ![]() безусловно должна
сворачиваться в
безусловно должна
сворачиваться в ![]() . Создается впечатление, что данная грамматика без
. Создается впечатление, что данная грамматика без ![]() -го правила есть LR(0)-грамматика. Что на самом деле неверно, в чём можно
убедиться, рассмотрев процесс LR(0)-разбор
-го правила есть LR(0)-грамматика. Что на самом деле неверно, в чём можно
убедиться, рассмотрев процесс LR(0)-разбор
При LR(k)-анализе применяется метод перенос-свертка (англ. shift-reduce). Суть метода сводится к следующему:
1. Программа анализатора читает последовательно символы входной строки до тех пор, пока не накопится цепочка, совпадающая с правой частью какого-нибудь из правил. Рассмотренные символы переносим в стек (операция перенос).
2. Далее все символы совпадающей цепочки извлекаются из стека и на их место помещается нетерминал, находящийся в левой части этого правила (операция свертка).
Метод перенос-свертка использует следующие компоненты:
§ входная строка,
§ стек (для запоминания рассмотренных символов),
§ управляющая таблица (для выбора следующего действия — перенос или свертка),
§ автомат (для запоминания информации о текущем состоянии стека).
1. Программа читает символ из входной цепочки.
2. Обращается к управляющей таблице.
3. Совершает соответствующее действие.
4. Возвращается к первому пункту, пока входная цепочка не закончится.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.




