


















Фундаментальные структуры данных
Хэш-таблицы
Пространственно-временной компромисс
Достижение компромисса между пространством и временем, т.е. между используемой памятью и временем работы алгоритма – вопрос, хорошо известный как теоретикам, так и практикам алгоритмики. Первый подход назовем улучшением входных данных. Он состоит в предварительной полной или частичной обработке входных данных с сохранением полученной дополнительной информации для ускорения позднейшего решения задачи. Второй подход назовем предварительной структуризацией. Он просто использует дополнительную память для того, чтобы обеспечить более быстрый и/или более гибкий доступ к данным.
Пространственно-временной компромисс
Имеется еще один метод разработки алгоритмов, относящийся к рассматриваемому пространственно-временному компромиссу, - это динамическое программирование. Он основан на записи решений перекрывающихся подзадач данной задачи в таблице, при помощи которой затем получается решение основной задачи. Заметим, что пространство и время не обязательно конкурируют друг с другом во всех ситуациях. Далее имеется очень важная область – сжатие данных, где снижение размера памяти является целью, а не способом решения другой задачи.
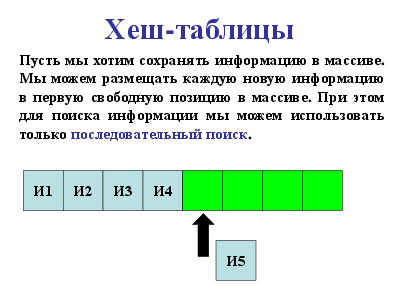
Хеш-таблицы
Пусть мы хотим сохранять информацию в массиве. Мы можем размещать каждую новую информацию в первую свободную позицию в массиве. При этом для поиска информации мы можем использовать только последовательный поиск.
И1
И2
И3
И4
И5
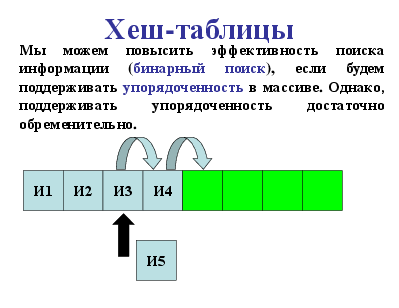
Хеш-таблицы
Мы можем повысить эффективность поиска информации (бинарный поиск), если будем поддерживать упорядоченность в массиве. Однако, поддерживать упорядоченность достаточно обременительно.
И1
И2
И3
И4
И5
Хеш-таблицы
Мы можем существенно повысить эффективность хранения и поиска информации, если вспомним, что компьютеры обладают замечательной способность обращаться к любому элементу массива по индексу практически за одинаковое малое время. Если бы удалось связать информацию напрямую с индексом массива, то мы получили бы возможность практически вгновенно размещать новую информацию или искать уже размещенную информацию в массиве. Для этого нам нужна функция: i = H(Информация), называемая хеш-функцией (функцией расстановки, функцией перемешивания). Она назначает каждой информации хеш-адрес.
Хеш-таблицы
Хеш-таблицы
Функция расстановки должна иметь значения между 0 и N-1, где N – размер таблицы. Х(ключ) = Q(ключ) % N где Q(ключ) – функция, принимающая целочисленное значение. Правило Люма: доля коллизий уменьшается, если размером таблицы выбрать целое N, не имеющее делителей, меньших 20. N можно взять, например, простым, но это не обязательно. Если количество ключей заранее известно, то тогда можно построить хэш-функцию не дающую коллизий.
Хеш-таблицы
Хеш-таблицы
В первом случае эффективность поиска зависит от длины связанных списков, которая, в свою очередь, зависит от количества введенной информации, размера таблицы и качества хэширования. Если хэш-функция распределяет n ключей по m ячейкам равномерно, то в каждом списке будет содержаться около n/m ключей. Отношение ά = n/m называется коэффициентом заполнения хэш-таблицы и играет ключевую роль в эффективности хеширования. В частности, среднее количество проверяемых узлов цепочек при успешном поиске S и при неудачном U равны, соответственно S ≈ 1 + ά/2 и U = ά.
Хеш-таблицы
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.