








Программная система статистического анализа одномерных наблюдений ISW
Краткое руководство пользователя
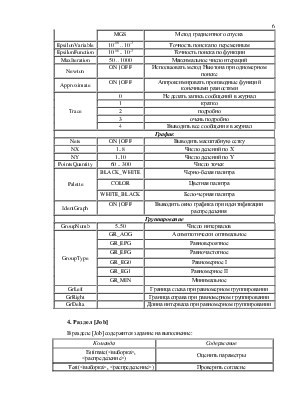
1. Широкий выбор моделей теоретических законов распределения, включающий порядка 30 стандартных законов и распределений, получаемых с помощью операций над этими стандартными моделями: операций сдвига, масштаба, смеси законов, произведения, усечения, логарифмирования.
2. Универсальный вид представления входных данных: негруппированные, группированные, цензурированные, частично группированные и интервальные выборки.
3. Группирование выборки в задачах оценивания и проверки гипотез может осуществляться четырьмя способами: в соответствии с асимптотически оптимальным (минимизирует потери информации Фишера при группировании), равновероятным, равночастотным и равномерным группированием.
4. Для
проверки согласия эмпирического распределения с теоретическим используются
восемь критериев: отношения правдоподобия, ![]() Пирсона,
Пирсона, ![]() Пирсона с
поправкой Никулина, типа Колмогорова, Смирнова,
Пирсона с
поправкой Никулина, типа Колмогорова, Смирнова, ![]() и
и ![]() Мизеса,
Реньи. На базе полученных результатов авторов проверка согласия гарантируется
как при проверке простых, так и проверке сложных гипотез.
Мизеса,
Реньи. На базе полученных результатов авторов проверка согласия гарантируется
как при проверке простых, так и проверке сложных гипотез.
5. Оценивание
параметров может осуществляться различными методами: максимального
правдоподобия, максимального правдоподобия с предварительной группировкой
наблюдений, MD-оценивания с минимизаций расстояния, измеряемого
статистиками типа Колмогорова, статистиками типа ![]() и
и ![]() Мизеса, с
использованием предложенных авторами оптимальных L-оценок
по выборочным квантилям.
Мизеса, с
использованием предложенных авторами оптимальных L-оценок
по выборочным квантилям.
6. На базе разработанных робастных методов оценивания реализована эффективная параметрическая процедура отбраковки аномальных наблюдений.
7. Графическая подсистема позволяет просматривать функции распределения, плотности, гистограммы, ядерные оценки плотности.
8. Разработаны средства для моделирования распределений статистик критериев согласия при различных сложных гипотезах и различных альтернативах. Это позволяет исследовать распределения статистик при различных сложных проверяемых гипотезах, строить приближенные математические модели этих распределений, исследовать мощность критериев относительно различных близких альтернатив.
9. На базе системы возможна организация исследований законов распределений различных статистик, вычисляемых при анализе одномерных наблюдений.
Параметры системы можно задать как в режиме диалога (Кнопка ![]() на
панели инструментов), так и в файле инициализации is.ini.
на
панели инструментов), так и в файле инициализации is.ini.
В файле содержатся ключевые слова разделов, команды инициализации и комментарии.
· Ключевые слова разделов
[Distributions]
<Список распределений>
[Samples]
<Список выборок>
[Options]
<Параметры>
[Job]
<Задание на выполнение>
· Команды
Разделы состоят из наборов команд, причем в одной строке может быть только одна команда. Каждая команда имеет следующий формат:
[<идентификатор> =] <процедура> (<список параметров>)
<идентификатор> - это уникальное имя объекта, инициализируемого процедурой <процедура>, состоит из не более чем 30 букв и цифр без пробелов и управляющих символов. Идентификатор может использоваться в качестве параметров других процедур.
<список параметров> - это набор параметров процедуры <процедура>, разделенных запятой.
· Комментарии
Комментарием считается любая строчка, начинающаяся с символа «*» или «//».
В этом разделе происходит инициализация списка распределений. Распределение инициализируется командой
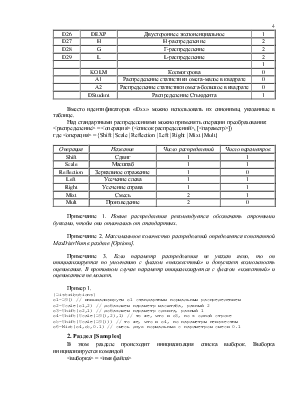
<распределение> = {D0 | D1 | D2 | ... | D29} ([<список параметров>]), где D0, D1, ... , D29 - это зарезервированные в системе идентификаторы распределений:
|
Иденти-фикатор |
Синоним |
Название распределения |
Число пара-метров |
|
D0 |
UNIFORME |
Равномерное |
0 |
|
D1 |
EXP |
Экспоненциальное |
0 |
|
D2 |
SEMI_NORM |
Полунормальное |
0 |
|
D3 |
RELEY |
Релея |
0 |
|
D4 |
MAXWELL |
Максвелла |
0 |
|
D5 |
CHI |
Модуля n-мерного нормального распределения |
0 |
|
D6 |
PARETO |
Парето(2.0000) |
1 |
|
D7 |
ERL |
Эрланга |
1 |
|
D8 |
LAPLACE |
Лапласа |
0 |
|
D9 |
NORM |
Нормальное |
0 |
|
D10 |
LN_NORM |
Логарифмически(ln) Нормальное |
2 |
|
D11 |
LG_NORM |
Логарифмически(lg) Нормальное |
2 |
|
D12 |
CAUCHIE |
Коши |
0 |
|
D13 |
LOGIST |
Логистическое |
0 |
|
D14 |
VEI |
Вейбулла |
1 |
|
D15 |
MIN |
Минимального значения |
0 |
|
D16 |
MAX |
Максимального значения |
0 |
|
D17 |
G_MIN |
Обобщенное мин. значения |
1 |
|
D18 |
NAK |
Накагами |
1 |
|
D19 |
GAMMA |
Гамма |
1 |
|
D20 |
BETA_I |
Бета 1-го рода |
2 |
|
D21 |
BETA_II |
Бета 2-го рода |
2 |
|
D22 |
BETA_III |
Бета 3-го рода |
3 |
|
D23 |
SB_J |
Sb-Джонсона |
2 |
|
D24 |
SL_J |
Sl-Джонсона |
2 |
|
D25 |
SU_J |
Su-Джонсона |
2 |
|
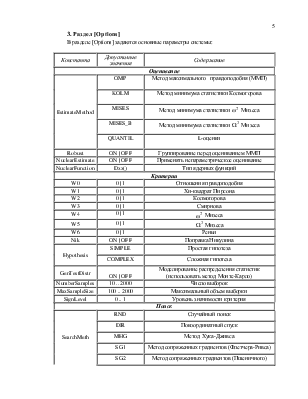
D26 |
DEXP |
Двустороннее экспоненциальное |
1 |
|
D27 |
H |
H-распределение |
2 |
|
D28 |
G |
Г-распределение |
2 |
|
D29 |
L |
L-распределение |
2 |
|
1 |
|||
|
KOLM |
Колмогорова |
0 |
|
|
A1 |
Распределение статистики омега-малое в квадрате |
0 |
|
|
A2 |
Распределение статистики омега-большое в квадрате |
0 |
|
|
DStudent |
Распределение Стьюдента |
1 |
Вместо идентификаторов «Dxx» можно использовать их синонимы, указанные в таблице.
Над стандартными распределениями можно применять операции преобразования:
<распределение> = <операция> (<список распределений>, [<параметр>])
где <операция> = {Shift | Scale | Reflection | Left | Right | Mixt | Mult}
|
Операция |
Название |
Число распределений |
Число параметров |
|
Shift |
Сдвиг |
1 |
1 |
|
Scale |
Масштаб |
1 |
1 |
|
Reflection |
Зеркальное отражение |
1 |
0 |
|
Left |
Усечение слева |
1 |
1 |
|
Right |
Усечение справа |
1 |
1 |
|
Mixt |
Смесь |
2 |
1 |
|
Mult |
Произведение |
2 |
0 |
Примечание 1. Новые распределения рекомендуется обозначать строчными буквами, чтобы они отличались от стандартных.
Примечание 2. Максимальное количество распределений определяется константой
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.