Относительная дешевизна вычислительного кластера по сравнению с суперкомпьютерами и корпоративными компьютерными кластерами достигается за счет некоторого снижения эффективности (узкое место – относительно низкая пропускная способность и относительно высокая латентность локальных сетей даже при использовании GigabitEthernet) и за счет существенного снижения функциональности (основная работа по распараллеливанию процессов и памяти выполняется разработчиком ПО, а сами задачи запускаются в пакетном режиме и не допускают интерактивного управления). Эти недостатки существенно сужают область применимости вычислительных кластеров, ограничивая ее, в основном, задачами исследовательского и научно-технического характера. С другой стороны, сочетание дешевизны и гибкости с использованием стандартных операционных систем (Unix/Linux) позволяет создавать вычислительные кластеры, что называется, «под столом» - например, на базе двух домашних компьютеров (не говоря уже об учебном дисплейном классе).
Примеры конфигураций двух российских вычислительных кластеров приведены в Приложении.
Корпоративный кластер занимает промежуточное положение между суперкомпьютером и вычислительным кластером как по стоимости, так и по производительности, но значительно опережает представителей этих классов по показателям надежности. Именно корпоративные кластеры используются при создании систем высокой и непрерывной готовности и отказоустойчивых систем, поэтому за ними закрепилось второе название – кластеры высокой доступности (HA clusters).
Число узлов корпоративного кластера и число процессоров на узле связаны обратной зависимостью по отношению к вычислительному кластеру: стандартная конфигурация первого содержит небольшое число узлов со значительным числом процессоров (хотя и существенно меньшим, чем у суперкомпьютера), стандартная конфигурация второго содержит значительное число узлов с небольшим числом процессоров - так что произведения этих чисел для кластеров одного масштаба примерно равны.
Высокая доступность данных в корпоративном кластере обеспечивается следующими архитектурными решениями:
- создание высоконадежной системы хранения данных (СХД), которая отсутствует как в суперкомпьютерах, так и в вычислительных кластерах и одним из основных компонентов которой является система резервного копирования;
- использование для связи между узлами кластера коммуникационной системы (heartbeat), основанной на специальной высокоскоростной среде передачи данных с низкой латентностью, такой как SCI, HP HyperPlex или Sun WildCat;
- обеспечение доступа всех узлов кластера к общему дисковому пространству, реализованному на отказоустойчивом дисковом массиве RAID-0, RAID1+0 или RAID-5.
Поскольку протокол SCSI не обеспечивает устойчивой работы шины с более чем двумя инициаторами, для кластера, состоящего из многих узлов, наилучшей инфраструктурой доступа серверов к общему дисковому массиву в настоящее время признается SAN (Storage Area Network) – сеть хранения данных.
Конфигурация простейшего корпоративного кластера из двух узлов показана на рисунке 8.
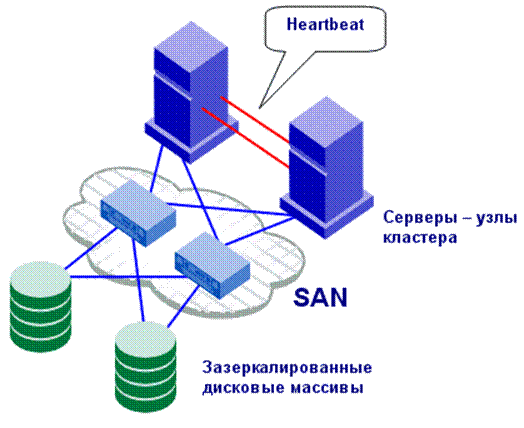
Рис. 8. Конфигурация простейшего корпоративного кластера.
Помимо упомянутых выше компонентов архитектуры, специфической чертой кластеров высокой доступности является наличие специального кластерного ПО для обеспечения высокой доступности информационных сервисов (функциональных процессов), реализуемых кластером. Ядром этого ПО являются системные демоны или системные скрипты, отслеживающие работоспособность информационных сервисов, которые выполняются на узлах кластера. В случае сбоя в работе какого-либо информационного сервиса, вызванного отказом диска, сетевого интерфейса или самого приложения, выполнение сервиса переносится на другой узел кластера. Под переносом здесь понимается: остановка приложения (если оно еще работало) на первом узле, размонтирование общих дисковых томов, монтирование общих дисковых томов на втором узле, перенос IP-адреса (или алиаса) с первого на второй узел, запуск приложения. Если в кластере больше двух узлов, то информационные сервисы вышедшего из строя узла переносятся на другие узлы в зависимости от политики, заданной либо администратором, либо определенной кластерным ПО на основе данных о загрузке работоспособных узлов.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.