Depending on where the training and validation sets are generated, we have three RT-based training mechanisms, and depending on the crossover operator used we have four GA-based training mechanisms. The RT-based training mechanism is a new way of training an ANN based on its past training experience and weights reduction (Nastac and Costea, 2004). In addition to what has been reported in the literature (e.g. Pendharkar and Rodger, 2004), we introduce a new crossover operator (multipoint crossover) and test its performance against classical one-point, arithmetic and uniform crossovers.
We define six hypotheses. Hypotheses H1, H2, and H3 are concerned with the individual influence of each of the three factors on the prediction performance of the ANN. The results show a very strong support for all three hypotheses. Concerning H1, we found that when the starting solution has relatively low accuracy rates (80–90%) the GA outperformed the RT mechanism, whereas the difference was smaller to non-existent when the starting solution had relatively high accuracy rates (95–98%). This can be considered a normal result, since we do not expect great improvements starting from an already very good solution. It would be interesting in future studies to check whether these hybrid approaches overcome the classical ones (those where the weights of the ANN are randomly initialized). The validation of H2 shows that preprocessing method has an influence on the ANN performance, with normalization achieving the best results. In line with Pendharkar (2002), the validation of H3 shows that increasing kurtotic data distributions hurt the performance of ANN during both the training and the testing phases.
Hypothesis H4 tests the influence of crossover operator on the prediction performance of a GAbased ANN. As was reported (Yao, 1999; Pendharkar and Rodger, 2004), the crossover operator seems to have no impact on the classification performance of GA-based ANNs. The fifth hypothesis (H5) tests whether the point at which we split the data into effective training and validation sets has any impact on the prediction performance of an RT-based ANN. We found no difference in RTbased ANN training performance for all three RT-based mechanisms.
The main hypothesis (H6) concerns the individual and combined influence of the three factors on the prediction performance of ANNs. In experiment 5 we tested H6 by performing a three-way ANOVA: again, all individual factors have a statistically significant influence on both the ANN training and the ANN testing performances. At the same time, the influence of any combination of the three factors was found to be statistically significant. The results of pairs’ comparisons for each factor once again validate the first three hypotheses.
In our experiments, RT was much faster than the GA. Therefore, when time is a critical factor, RT can be taken into consideration as long as there is no major difference between the performances of these two approaches. The GA-based ANN needs around 1000 generations for each training operation. Other stopping criteria may be employed to make the GA training faster. Further research may be focused on tuning the GA parameters to make the GA training more efficient.
ACKNOWLEDGEMENTS
We wish to thank Jonas Karlsson for providing us the telecom dataset and Barbro Back for her valuable comments. We would like to thank two anonymous reviewers for very useful comments and criticisms.
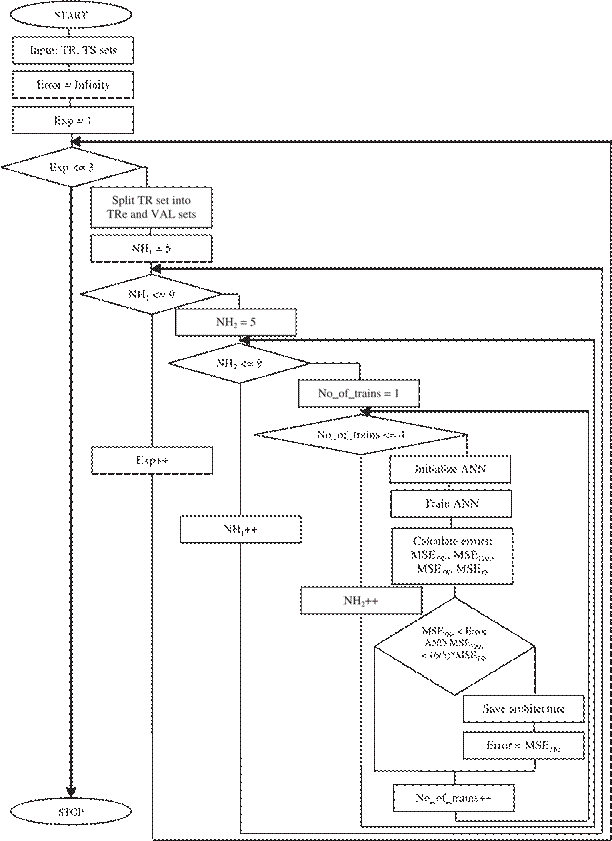
Figure A.1. Flowchart of the empirical procedure to determine ANN architecture
REFERENCES
Alander JT. 1995. Indexed bibliography of genetic algorithms and neural networks. Report 94-1-NN, University of Vaasa, Department of Information Technology and Production Economics, 1995. ftp://ftp.uwasa.fi/cs/ report94-1/gaNNbib.ps.Z, key: gaNNbib.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.