таким чином виключається сезонна складова; щод дати оцінку сезонній складовій S^ слід розділити Yt на Yt’ (без сезонного фактору).
Для одержання оцінки тренду слід побудувати модель тренду. Припустимо, що тренд має лінійну модель, тобто Yt’=Tt*It=a+b*t+Ut; за МНК Yt’^=126,52+1,83t
Ця модель непогано описує дійсність. Випадкова складова І=1. Оскільки дані спостереження Yt’ починаються з третього квартала 1981 р., також дану модель можна розгядати за допомогою МНК (експоненційна залежність)
![]()
ln Yt = ln a0+l*t+a1*q1*t+a2*q2*t+a3*q3*t+Ut
q1, q2, q3 – штучні змінні, показують вплив на У певного кварталу. Ці змінні мають специфіку: змінна q1 приймає значення 1 в першому кварталі, q2 – в другому кварталі, q3 – в третьому кварталі. Коли всі змінні дорівнюють 0 – четвертий квартал.
|
Кв-л |
q1 |
q2 |
q3 |
|
I |
1 |
0 |
0 |
|
II |
0 |
1 |
0 |
|
III |
0 |
0 |
1 |
|
IV |
0 |
0 |
0 |
Для інформації про всі квартали досить 3-х змінних.
Отримані а1^ – показує наскільки зв’язані між собою І та IV квартали
a2^ – між II i IV
a3^ – між III i IV
a1^ – оцінка Ш кварталу, коли всі інші не впливають на І і т.д.
Щоб визначити окремо вплив кожного кварталу на І, треба побудувати модель, прирівнюючі змінні q до 0 і залишивши лише ту змінну, що відповідає певному кварталу. Наприклад, якщо ми хочемо показати вплив І кварталу, тоді q2, q3=0, модель має вигляд: ln a0 + l*t + a1*q1*t
3. Метод рухомого середнього та його особливості
Метод рухомого середнього – усереднює n попередніх значень (фактичних значень показника У) і видає його як прогноз на t+1 період. Прогнозне значення,
![]()
n – степінь рухомого середнього
Рухоме середнє 5-го порядку: Ft+1=1/5*(yt+yt-1+yt-2+yt-3+yt-4)
Недоліки методу:
1) всім спостереженням дається однакова вага, але більш свіжі дані важливіші для прогнозу, тобто мають більш вагу.
2) Крім того, ряд не має історії, обриває спостерження.
3) при появі нового числа, треба перераховувати весь прогноз.
Можна зменшити недоліки:
Ft+1 =0,4*yt+0,3*yt-1+0,2*yt-2+0,1*yt-3 – вага спадає при старінні даних.
4. Метод експоненційного згладжування
Недоліків методу рухомого середнього немає у методі експоненційного згладжування.
Метод експоненційного згладжування – найбільша вага надається найближчому спостереженню, а потім вага всіх спостережень спадає в геометричній прогресії.
Вага спостережень спадає в такому порядку:
a+ a*(1-a) + a*(1-a)2
Прогноз на t+1 період: Ft+1 = a*Yt + (1-a)*Et,
Тобто в сумі ці коефіцієнти дають 1.
Або Ft+1 = Ft + a*(Yt - Ft) = Ft + a*et, де (Yt - Ft) – похибка прогнозу
a – кореляція похибки, вона визначає швидкість старіння даних, або швидкість, з якою новий прогноз пристосований до похибки. Якщо a=0 – пристосування до похибки немає, a=1 – повне пристосування до похибки. Звичайно, aбереться в цифрах: a=[0,05; 0,01; 0,02; 0,03]. Але якщо ми нехтуємо дуже великими рядами, і хочемо, щоб проноз був чутлим до свіжих даних, тоді a=0,7 і більше.
Тобто, якщо чутливість прогнозу до даних велика (реагує на всі нові спостереження), тоді a прямує до 1. Якщо хочемо, щоб прогноз був нечутливим до змін даних, тоді a менше 0,3.
Переваги:
1) при появі нових даних не треба перераховувати всю схему спочатку, для одержання наступного значення прогнозу слід знати поточне значення попереднього спостереження yt і прогнозне його значення на час t: yt^.
Якщо порівняти ці 2 методи
(n-1)/2 = (1-a)/2 – це співвідношення показує, що чутливість методу рухомого середнього залежить від довжини ряду, а чутливість методу експотенц. згладжування – тільки від a. Прирівняємо і отримаємо, що
|
a |
0,05 |
0,1 |
0,2 |
0,3 |
|
n |
39 |
19 |
9 |
6 |
Для методу експот. зглад. – важливо встановити:
1) параметр a;
2) визначити довжину ряду, що згладжується;
3) визначити початкове значення (F0) прогнозу
F1 = a*y1 + (1-a)*F0, де y1 – поточне значення. Тому важливо знати значення F0.
Для цього існує кілька шляхів:
1) методом рухомого середнього знайти це значення з кількох попередніх спостережень
2) якщо ряд не має тренду, F0 можна прирівняти до у--;
3) F0 = y1 при Ft+1 = a*yt + (1-a)*Ft
Вибір a – залежить від даних. При аналізі даних сталої економіки – менш чутливий прогноз, великі ряди спостережень, a менше 0,3. При несталих процесах – менші ряди, a – велике.
Довжина бази прогнозу – пов’язана з вибором великих a. Крім цього, якщо ряд великий, то вибір початкового значення F0 стає не принциповим.
Розглянемо експериментальний метод (метод експертної виборки): спочатку задаємо a, наприклад, a=0,05.
Дані спостережень ділимо на 2 частини: перша – дані, за якими буде розрахована прогнозна функція; 2 – експериментальні, за якими буде визначена якість прогнозу.
1 частина : у1...уk 2 частина: yk+1 ...yn
Методом експ. згладж. визначимо прогноз Fk+1 за даними І частини. При цьому F0 визначається як рухоме середнє 3-го порядку: F0 = (y1 + y2 + y3)/3 або просто F0=y1.
Визначимо помилки прогнозу: е1=yk+1 - Fk+1
Далі ряд спостережень (І част.) зсуваємо на 1: у2, у3, ..., уk+1. На його основі визначаємо прогноз Fk+2 і розраховуємо похибку прогнозу e2 = yk+2 - Fk+2. В результаті отримаємо n-k похибок і зможемо розрахувати якість прогнозу за одним із показників:
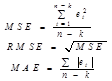
Потім, змінюючи значення a=0,1, повторюємо процедури. Так для всіх a (поки не =1). Потім порівнюємо показники якості, вибираємо найкраще a.
На основі методу експотенц. зглад. можна розрхувати і похибки прогнозу. Наприклад, МАЕt+1 = a*|et| + (1-a)MAE
Метод рухомого середнього має різні модифікації: метод Ханта, метод подвійного згладжування Брауна, метод Холта-Вінтера, метод Бокса - Дженкінса – застосовуються для визначення авторегресійних функцій і тому будуть розглянуті пізніше.
5. Вибір характеристик згладжування
Для методу експоненційного згладжування важливо правильно вибрати характеристики:
1) параметр a;
2) визначити довжину ряду, що згладжується;
3) визначити початкове значення (F0) прогнозу
1) Вибір a – залежить від даних. При аналізі даних сталої економіки – менш чутливий до нових даних прогноз, великі ряди спостережень, a менше 0,3. При несталих процесах – менші ряди, a – велике.
Якщо a=0 – пристосованності до похибки нема; якщо a=1 – пристосованість до похибки повна. зазвичай a береться в діапазоні [0,05;0,3]. Але якщо ми хочемо, щоб прогноз був чутливим до свіжих даних, тоді a береться в діапазоні [0,6;0,9]. Тобто, якщо чутливість прогнозу велика (реагує на всі нові спостереження), то aÞ1.
2) визначити довжину ряду згладжування:
Довжина бази прогнозу – пов’язана з вибором великих a. Крім цього, якщо ряд великий, то вибір початкового значення F0 стає не принциповим.
3) F1 = a*y1 + (1-a)*F0, де y1 – поточне значення. Тому важливо знати значення F0.
Для цього існує кілька шляхів:
1) методом рухомого середнього знайти це значення з кількох попередніх спостережень
2) якщо ряд не має тренду, F0 можна прирівняти до у--;
3) F0 = y1 при Ft+1 = a*yt + (1-a)*Ft
6. Економетричне прогнозування
Економетричні методи – базуються на правильно побудованій економетричній моделі – є каузальною (роз’яснює змінення у не просто в часі, а як функцію від інших економічних показників – причинно-наслідкові зв’язки між економічними показниками).
Етапи прогнозування:
1. постановка задачі
2. побудова матем. моделі (залежності)
3. збір та вивчення необхідної інформації
4.оцінювання параметрів моделі з метою встановлення її відповідності попереднім припущенням з етапу 2
5.якщо передумови моделі не виконуються, змінюється специфікація моделі або застосовуються інші методи оцінювання її параметрів
6. після того, як знайдено відповідну теоретичну модель, зробити верифікацію моделі, з’ясувати її прогнозні властивості
Вимоги до моделі:
1) модель відповідає теоретичним гіпотезам економіки, які підтверджуються даними спостережень
2) оцінені параметри моделі повинні бути статистично значимими
3) прогнозні властивості моделі повинні задовольняти як статистичним показникам якості (стандартна похибка) так і економічній теорії
І етап – постановка задачі – треба добре розумітись на предметній області
ІІ етап – побудова мат. моделі. Мат. модель має певну специфікацію. Найбільш проста модель: yt=a0+a1*xt1+a2*xt2+... +ak*xtk+Ut – регресія у – залежна змінна; х – параметр
yt= f(xt)+Ut – закон розподілу випадкової величини
Припускаємо, Е(Ut) = 0, Е(Ut,Ut+t)=0 при t ¹0, а при t = 0, Е(Ut,Ut+t)=(s u)2 = const (нормальний закон розподілу).
Також : х не залежні, тобто не корелюють між собою та з випадковимою вел-ною U.
Економетр. моделі можуть складатись з систем рівнянь (наз. системи одночасних рівнянь). Розглянемо для прикладу спрощену модель Кейнса. Дана модель розглядає економіку на макрорівні; при цьому нас цікавить залежність нац. доходу від інших показників,
Yt=Ct+It+Gt (відповідно споживання, інвестиції, держ. витрати)
В таких моделях змінні поділяються на екзогенні (задаються поза моделлю) та ендогенні (значення яких визначаються за допомогою моделі). В нашій моделі: Yt – ендогенна; Ct – ендогенна, повинна бути включена в модель.
Спрощено: Ct =a0+a1(Yt-Tt)+U1t, де Yt – доходи, Tt – податки.
It=b1*Yt-1+b2*Rt+U2t, де Yt – капітал, Rt – відсоткова ставка.
Gt,Tt, Rt – екзогенні змінні (спрощено)
M1 – касові залишки
Від Rt залежать М1, також М1 залежать від Нt, інші залежності, але ми поки що від них відмовимось.
Yt-1 – лагова ендогенна змінна – вважаємо, що на період t це значення буде відомо, тому вважаємо її наперед визначеною, вона відноситься до пояснюючих змінних.
Для розрахунку параметрів структурної форми моделі використовується приведена форма, коли кожна ендогенна змінна виражається тільки через наперед визначені змінні (екзогенні або лагові).
В наведеній формі рівнянь стільки, скільки є невідомих. Коефіцієнти в цих рівняннях відповідають економічним мультиплікаторам. Щоб отримати приведену форму, зробимо підстановки.
Yt=a0/(1-a1)+b1/(1-a1)*Yt-1+b2/(1-a1)*Rt+1/(1-a1)*Gt–a1/(1-a1)*Tt+E1
Ct=a0/(1-a1)+{a1*b1/(1-a1)*Yt-1+(a1*b2/(1-a1)}*Rt+a1/(1-a1)*(Gt-Tt)+E2
It=b1*Yt-1+2*Rt+E3
Для нац. доходу (1) розглянемо коеф-т при Gt:
1/(1-a1)=1/(1-0,6)=2,5 – мультиплікатор
a1 – коеф-т граничного споживання, a1»0,6 – на світовому рівні.
Якщо Gt зросте на 1, тоді Yt зросте на 2,5
Економетр. модель в приведеній формі дозволяє визначити параметри a та b, а також має екон. зміст.
Всі макромоделі будуються як системи. Перед тим, як розв’язувати параметри структурної форми моделі, слід визначити, чи є окремі рівняння моделі ідентифікованими, чи ні. Якщо рівняння не ідентифіковані, не знайдемо вірну модель.
Якщо в рівнянні кількість пропущених екзогенних та ендогенних змінних дорівнює кількості ендогенних змінних
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.

