Эффективность методов поиска определяется величиной потерь на поиск, под которыми будем понимать число определений функции качества, необходимое для того, чтобы система в среднем сместилась к цели на величину рабочего шага. Предположим, что перед каждым рабочим шагом известно градиентное направление. Тогда для достижения цели потребуется некоторое число шагов Мгр, т.е. Мгр раз определяется направление градиента и выполняется рабочий шаг. В действительности для исследуемого алгоритма потребуется количество шагов, отличное от Мгр , т.е. потребуется иное количество измерений целевой функции. Обозначим это количество измерений через М. Тогда потери на поиск определяются следующим образом
![]() , (5.95)
, (5.95)
где ![]() .
.
Величина 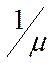 показывает, на какую долю
градиентного шага в среднем сместиться система в сторону экстремума при одном
поисковом шаге, так как система смещается к цели лишь в результате благоприятных
шагов, то обозначив число благоприятных шагов через m , будет удобно вместо пользоваться
понятием среднего смещения не за один поисковый шаг вообще, а за один
благоприятный шаг. Тогда смещение за один благоприятный шаг
показывает, на какую долю
градиентного шага в среднем сместиться система в сторону экстремума при одном
поисковом шаге, так как система смещается к цели лишь в результате благоприятных
шагов, то обозначив число благоприятных шагов через m , будет удобно вместо пользоваться
понятием среднего смещения не за один поисковый шаг вообще, а за один
благоприятный шаг. Тогда смещение за один благоприятный шаг
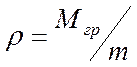 , (5.96)
, (5.96)
где ![]() .
.
Если величина градиентного шага ![]() ,
то
,
то ![]() r будет величиной среднего
благоприятного шага при случайном выборе направления движения, т.е. при
случайном изменении угла
r будет величиной среднего
благоприятного шага при случайном выборе направления движения, т.е. при
случайном изменении угла ![]() в интервале
в интервале ![]() . При
. При ![]() ;
; ![]()
![]() . (5.97)
. (5.97)
Математическое ожидание ![]() определяется из
выражения
определяется из
выражения
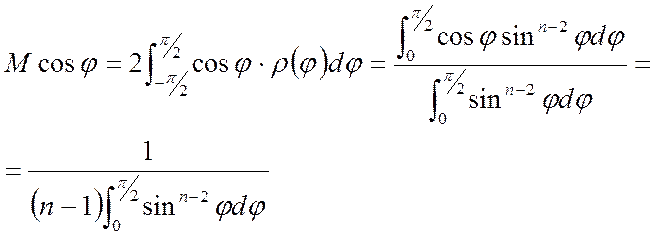 , (5.98)
, (5.98)
где 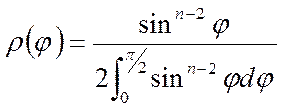 - плотность распределения угла
- плотность распределения угла ![]() в n-мерном
пространстве при равновероятном выборе направлений случайных шагов. Выражение
для
в n-мерном
пространстве при равновероятном выборе направлений случайных шагов. Выражение
для ![]() впервые было получено Л.А.Растригиным
/2,118/. Очевидно, что для метода градиента
впервые было получено Л.А.Растригиным
/2,118/. Очевидно, что для метода градиента ![]() .
.
Следует отметить, что соотношение (5.98) является применимым для тех
алгоритмов случайного поиска, для которых интервал благоприятных направлений ![]() не разбит на дискретные части
(удачные, результативные и т.д.).
не разбит на дискретные части
(удачные, результативные и т.д.).
Из выражений (5.95) и (5.96) следует , что
![]() ,
,
т.е. для
определения потерь на поиск помимо ![]() необходимо вычислить
соотношение
необходимо вычислить
соотношение ![]() для каждого алгоритма. Это
соотношение показывает сколько измерений функции качества необходимо
произвести, чтобы в среднем получить один благоприятный шаг движения системы.
для каждого алгоритма. Это
соотношение показывает сколько измерений функции качества необходимо
произвести, чтобы в среднем получить один благоприятный шаг движения системы.
В связи с тем, что основной особенностью методов случайного поиска является некоторая неопределенность результата оптимизации, связанная со случайным характером самого поиска, естественно, необходимо ввести процедуру накопления, позволяющую улучшить дисперсные свойства случайного поиска.
Рассмотрим два наиболее распространенных вида накопления информации при случайном поиске:
- поиск по наилучшей пробе;
- метод статистического градиента /118/.
Сущность поиска по наилучшей пробе заключается в следующем. Пусть для
сбора информации из исходного состояния Хо
делается ![]() случайных пробных шагов. длиной g:
случайных пробных шагов. длиной g:
![]() , (5.99)
, (5.99)
и определяется m значений функции качества:
![]() , (5.100)
, (5.100)
В соответствие с алгоритмом по наилучшей пробе рабочий шаг делается в направлении наибольшего уменьшения функции качества
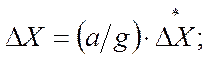 (5.101)
(5.101)
где а - величина рабочего шага, а 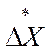 соответствует наилучшей пробе из
имеющихся
соответствует наилучшей пробе из
имеющихся
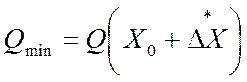 . (5.102)
. (5.102)
Потери на поиск для этого алгоритма выражаются соотношением
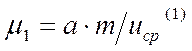 ,
(5.103)
,
(5.103)
где 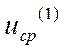 - среднее смещение вдоль градиента
на рабочем шаге.
- среднее смещение вдоль градиента
на рабочем шаге.
При
![]() система будет двигаться вдоль
градиента функции качества
система будет двигаться вдоль
градиента функции качества
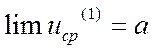 ,
,
а дисперсия проекции рабочего смещения на градиентное направление
![]() .
.
На рис.5.23 показано поведение потерь на поиск для этого алгоритма, а на рис.5.24 поведение дисперсии рабочего смещения для различных значений размерности пространства регулируемых параметров n и числа пробных шагов m. В настоящее время разработано несколько различных модификаций этого алгоритма, отличающихся потерями на поиск и дисперсией рабочего смещения движения системы от направления градиента.
Второй наиболее распространенный алгоритм случайного поиска - алгоритм статистического градиента, реализует другой способ накопления, где используется значительно большая часть полученной информации. На базе m+1 проб образуется векторная сумма
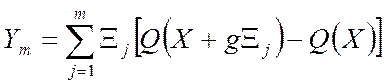 . (5.104)
. (5.104)
Относительно этой суммы в случае линейного поля можно высказать два очевидных положения, которые являются частным случаем теорем, рассмотренных в работе /118/:
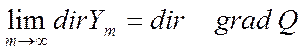 ,
(5.105)
,
(5.105)
где ![]() - направление Z, т.е. с ростом числа проб направление
векторной суммы (5.104) стремится к градиентному:
- направление Z, т.е. с ростом числа проб направление
векторной суммы (5.104) стремится к градиентному:
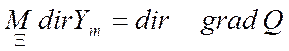 , (5.106)
, (5.106)
т.е.
математическое ожидание направления этой суммы по всем возможным реализациям
случайных проб ![]() совпадает с градиентным
направлением, независимо от числа проб m.
совпадает с градиентным
направлением, независимо от числа проб m.
Эти два положения позволяют утверждать, что оценка градиентного
направления в виде вектора (5.104) будет несмещенной и в пределе при ![]() совпадает с градиентным
направлением. Запишем формулу (5.104) в виде рекуррентного соотношения
совпадает с градиентным
направлением. Запишем формулу (5.104) в виде рекуррентного соотношения
![]() , (5.107)
, (5.107)
где ![]() - параметр забывания предыстории,
при этом случай (5.104) соответствует
- параметр забывания предыстории,
при этом случай (5.104) соответствует ![]() ;
;
![]() ;
; ![]() -
угол между вектором случайного шага
-
угол между вектором случайного шага ![]() и направлением
градиента функции качества;
и направлением
градиента функции качества; ![]() ;
; ![]() - величина пробного шага.
- величина пробного шага.
Потери на поиск для этого алгоритма выражаются формулой
![]() ), (5.108)
), (5.108)
где ![]() - среднее смещение вдоль градиента
на рабочем шаге. На рис. 5.25 представлено поведение среднего рабочего
смещения к цели, величины, обратной потерям (5.108) данного алгоритма, для
различных значений n как функции
числа проб m при k = 1. На рис.5.26 показано изменение
дисперсии рабочего смещения при движении системы к цели как функции числа
проб.
- среднее смещение вдоль градиента
на рабочем шаге. На рис. 5.25 представлено поведение среднего рабочего
смещения к цели, величины, обратной потерям (5.108) данного алгоритма, для
различных значений n как функции
числа проб m при k = 1. На рис.5.26 показано изменение
дисперсии рабочего смещения при движении системы к цели как функции числа
проб.
Как и следовало ожидать, потери на поиск увеличиваются, а дисперсия уменьшается с увеличением числа проб.
Для сравнения представленных алгоритмов случайного поиска рассмотрим их
характеристики в виде среднего смещения к цели на один шаг поиска ![]() в зависимости от
дисперсии рабочего смещения
в зависимости от
дисперсии рабочего смещения ![]() при различных
размерностях варьируемых параметров n,
представленных на рис.5.27.
при различных
размерностях варьируемых параметров n,
представленных на рис.5.27.
Из этого рисунка видно, что кластер соответствующий алгоритму статистического градиента (представлен сплошной линией) имеет преимущество перед алгоритмом поиска по наилучшей пробе как по дисперсии рабочего смещения так и по среднему смещению на один шаг поиска.
Однако с точки зрения сложности реализации алгоритм поиска по наилучшей пробе является значительно проще и предпочтительней при реализации в виде спецвычислителей на основе микропроцессорных комплектов.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.