Ця проста ідея може бути розширена - ми можемо додати потрібне число рівнів. Унизу на мал. 3.8 ми бачимо другий рівень, що дозволяє рухатися ще швидше першого. При пошуку елемента ми рухаємося по цьому рівні, поки не дійдемо до потрібного відрізка списку. Потім ми ще зменшуємо інтервал невизначеності, рухаючись по посиланнях 1-го рівня. Лише після цього ми проходимо по посиланнях 0-го рівня.
Вставляючи вузол, нам знадобиться визначити кількість вихідних від нього посилань. Ця проблема легше всього вирішується з використанням випадкового механізму: при додаванні нового вузла ми “кидаємо монету”, щоб визначити, потрібно чи додавати ще шар. Наприклад, ми можемо додавати чергові шари доти, поки випадає “решка”. Якщо реалізовано тільки один рівень, ми маємо справу фактично зі звичайним списком і час пошуку є O(n). Однак, якщо є достатнє число рівнів, розділений список можна вважати деревом з коренем на вищому рівні, а для дерева час пошуку є O(lg n).
Оскільки реалізація розділених списків містить у собі випадковий процес, для часу пошуку в них установлюються імовірнісні границі. При звичайних умовах ці границі досить вузькі. Наприклад, коли ми шукаємо елемент у списку з 1000 вузлів, імовірність того, що час пошуку виявиться в 5 разів більше середнього, можна оцінити як 1/1,000,000,000,000,000,000[5].
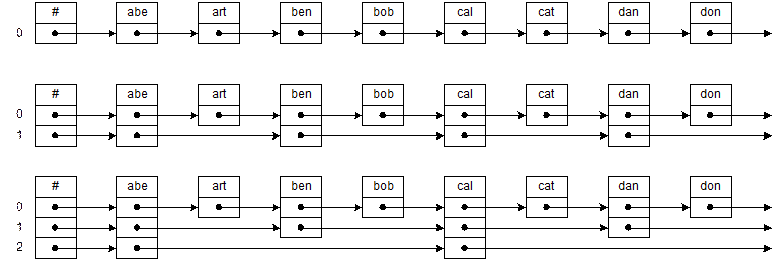
Рис. 0.8:Пристрій розділеного списку
Реалізація
Реалізація роботи з розділеними списками на Си перебуває в розділі 4.8. Оператори typedef T, а також compLT і compEQ варто змінити так, щоб вони відповідали даним, збереженим у вузлах списку. Крім того, знадобиться вибрати константу MAXLEVEL; її значення вибирається залежно від очікуваного обсягу даних.
Функція initList викликається на самому початку. Вона відводить пам'ять під заголовок списку й инициализирует його поля. Ознакою того, що список порожній, Функція insertNode створює новий вузол і вставляє його в список. Звичайно, insertNode спочатку відшукує місце в списку, куди вузол повинен бути вставлений. У масиві update функція враховує посилання, що зустрілися, на вузли верхніх рівнів. Ця інформація надалі використається для коректної установки посилань нового вузла. Для цього вузла, за допомогою генератора випадкових чисел, визначається значення newLevel, після чого приділяється пам'ять для вузла. Посилання вперед установлюються за інформацією, що містить у масиві update. Функція deleteNode видаляє вузли зі списку й звільняє займану ними пам'ять. Вона реалізована аналогічно функції findNode і так само шукає в списку видаляє узел, що.
Ми розглянули кілька методів організації словників: хеш-таблицы, незбалансовані двійкові дерева, чорний^-чорні-червоно-чорні дерева й розділені списки. Є трохи факторів, які впливають на вибір алгоритму в конкретній ситуації:
void WalkTree(Node *P) {
if (P == NIL) return;
WalkTree(P->Left);
/* Тут досліджуємо P->Data */
WalkTree(P->Right);
}
WalkTree(Root);
Node *P = List.Hdr->Forward[0];
while (P != NIL) {
/* Тут досліджуємо P->Data */
P = P->Forward[0];
}
¨ Для хеш-таблиц потрібно тільки один покажчик на вузол. Крім того, потрібна пам'ять під саму таблицю.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.