Как и любой математический метод, кластерный анализ не гарантирует получение «красивого» результата, но поможет по-новому взглянуть на имеющиеся данные, выявить в них неочевидные закономерности, даст последовательность рассмотрения потребителей для их сегментации.
1. Запустите SPSS (Пуск à Программы àSPSS for Windows àSPSS 11.5 for Windows).
2. Если откроется окно начального диалога с рамкой What would you like to do? (что Вы собираетесь делать), выберите опцию Type in data (вводить данные).
3. Введите данные.
В организации диалога SPSS много общего с программой Excel. Собранные в результате исследования данные хранятся в таблице Data view (просмотр данных, рис. Рис. 4). Столбцы этой таблицы называются Variables (переменные), а строки – Cases (наблюдения).
Для описания характеристик таблицы данных, в первую очередь – ее формата, служит таблица Variable view (просмотр переменных, рис. Рис. 5), расположенная в том же окне. Для перехода от одной таблице к другой используются ярлыки, подобные ярлыкам рабочих листов в Excel.
Число строк таблицы Variable view соответствует числу переменных (столбцов таблицы на листе Data view), а имена столбцов фиксированы. Первый столбец таблицы Variable view называется Name (имя переменной). Это имя помещается в заголовок столбца первой таблицы аналогично заголовку столбца Excel и должно начинаться с буквы. Для обеспечения возможности ввода русских букв надо выбрать View à Fonts à Набор символов à Кириллица. Здесь же можно изменить шрифт, его размер и написание букв (не рекомендуется). Второй столбец, имеющий название Type, содержит тип данных. В примерах будут использованы типы Numeric (числовой), String (строковый). Третий столбец, под заголовком Width (количество символов), предназначен для задания количества символов в столбце данных. Обычно его значение остается тем, которое задано по умолчанию. То же относится и к остальным столбцам.
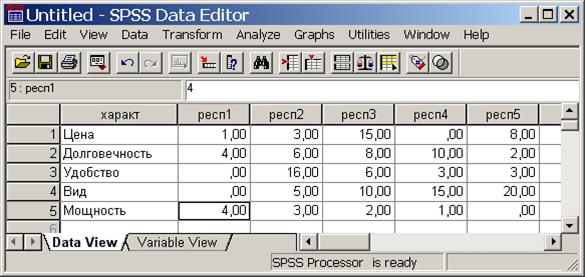
Рис. 4. Окно SPSS, лист Data view
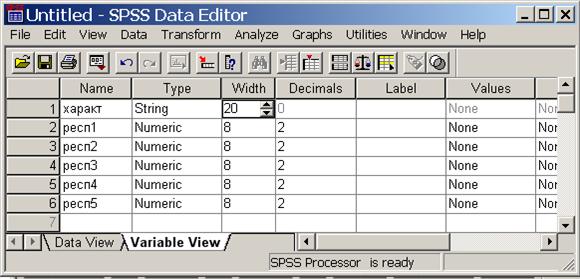
Рис. 5. Окно SPSS, лист Variable view
Заполните лист Variable view, как показано на рис. Рис. 5, а в лист Data view занесите рассчитанные значения взвешенной неудовлетворенности. На рис. 5 для примера показаны данные из первых пяти столбцов табл. 9.
4. Выберите Analyze à Classify à Hierarchical cluster… (Анализировать à Классифицировать à Иерархический кластерный [анализ]).
5. В появившемся окне перенесите все переменные, кроме первой, в поле Variable(s) из крайнего левого безымянного поля.
Выбор переменных – типовая операция, с которой начинается практически всякая задача анализа данных. Работа со списком переменных основывается на тех же принципах, что и работа с файлами и папками в Проводнике: одна переменная выделяется щелчком мыши, несколько – последовательными щелчками при нажатой клавише Ctrl или щелчком по первой из выделяемых переменных, а затем – по последней при нажатой клавише Shift.
Для переноса выделенных переменных в нужное поле нажмите кнопку со стрелкой, расположенную левее этого поля.
6. В рамке Cluster выберите радиокнопку Variables (переменные), так как группироваться будут респонденты, а им соответствуют столбцы. В рамке Display (отображение) снимите флажок Statistics (статистики), чтобы не перегружать окно результатов.
7. Задайте режимы вывода графической информации. Для этого щёлкните по кнопке Plots... (Диаграммы). Установите флажок Dendrogram (древовидная диаграмма). Посредством радиокнопки None (Нет) в рамке Icicle (сосулькообразная[15] [диаграмма]) отмените вывод диаграммы кластеризации.
Для выхода из окон задания режима используется кнопка Continue (продолжить). Для запуска вычислений после задания всех параметров – кнопка OK.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.