Переход к следующему производиться действием list *p; p=p->next;
Положительной стороной использования списков является меньшая трудоемкость вставки/удаления элемента по логическому номеру, а отрицательной – извлечение по логическому номеру и поиск значения.
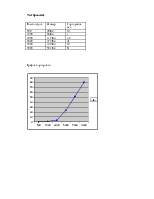
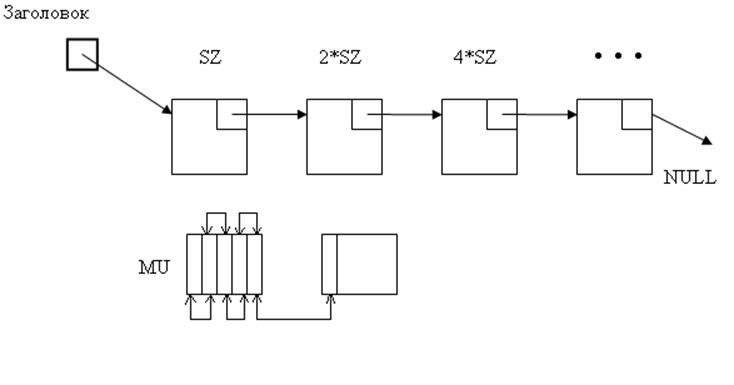
Структура данных представляет собой два уровня списков: в списке первого уровня находится указатель на динамический массив указателей на объекты., т.е. второй уровень, и информация необходимая для эффективной работы со структурой, а именно: количество элементов в подсписке. В массиве указателей находятся сами хранимые объекты, в данном случае – строка. Структура данных создается динамически, т.е. всё создается в ходе выполнения программы или загружается из файла. Структуре указатель на массив указателей.
В данном проекте реализована работа со списками, размерность массива указателей в каждом последующем элементе списка в 2 раза больше, чем в предыдущем.. При переполнении текущего массива указателей последний указатель переносится в следующий элемент списка.
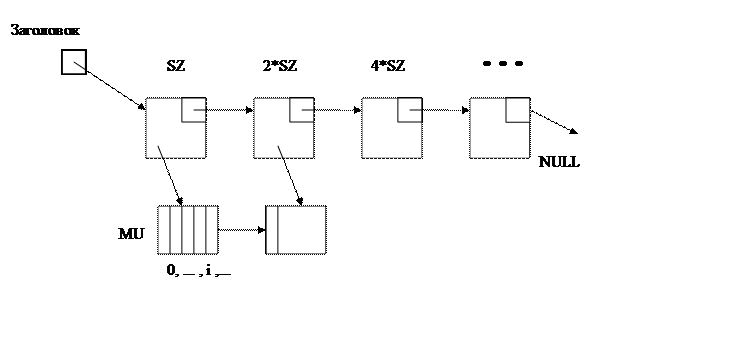
При добавлении нового объекта по вводимому логическому номеру происходит поиск места вставки, осуществляемый поочередным просмотром каждого элемента списка. Как только вводимый логический номер совпадает с логическим номером некоторого объекта в списке, происходит раздвижка, вследствие которой некоторый объект списка смещается вперед, последовательно сдвигая последующие объекты (если элемент списка оказывается переполнен, вызываем расширение), а новый объект становится на его место.
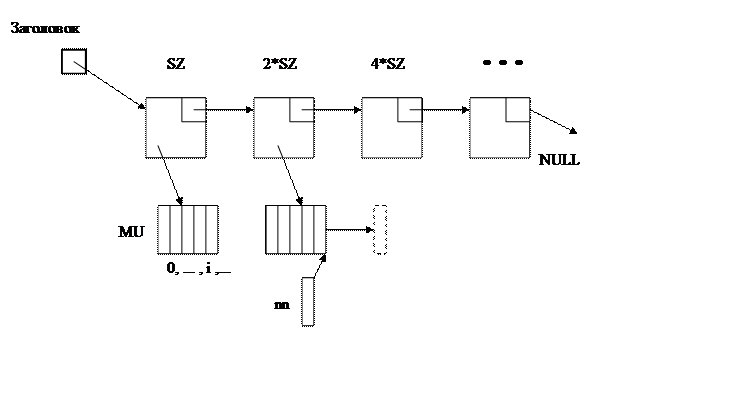
При извлечение по логическому номеру все начинается с того, что вводится некоторый логический номер, по которому и нужно и найти объект.
Далее в методе происходит поиск по этому логическому номеру объекта. Этот поиск осуществляется просмотром каждого элемента во всем списке на момент совпадения номера. Как только номер найден, происходит обращение к соответствующему объекту и возврат его в качестве параметра. Если поиск не дал результата, возвращаем нуль.
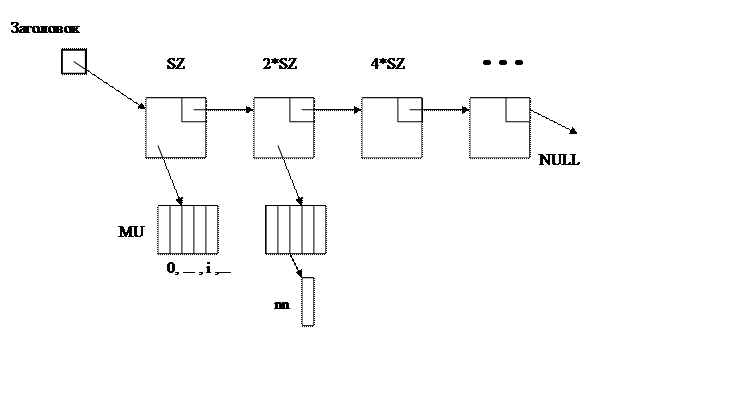
Используемый метод сортировки – метод «пузырька». Производится попарно сравнение элементов и перестановка, если пара расположена не в порядке возрастания. Просмотр повторяется до тех пор, пока при проверки объектов от начала списка и до конца перестановок больше не будет.
Оценить трудоемкость алгоритма можно через среднее количество сравнений, которое равно (n*n-n)/2
![]()
![]()
Загрузка из текстового файла основана на добавления в структуру данных. После открытия файла в режиме чтения, выделяется память под строки, и считываются последовательно все строки из файла в память.
Последовательный вывод списка основан на первоначальной проверке списка, затем происходит вывод содержимого элементами списка.
Для большего удобства в проекте реализовано меню, которое помогает пользователю ориентироваться в программе. С помощью меню Вы можете использовать (проверить, попробовать) все функции, описанные в проекте.
Для обеспечения взаимодействия с пользователем разработана структура команд:
printf("\n1=Add");
printf("\n2=Insert");
printf("\n3=Get");
printf("\n4=Print");
printf("\n5=Sort");
printf("\n6=Save");
printf("\n7=Exit");
Команды означают следующее:
1---Add --- вставить новый объект в конец списка.
2--- Insert--- вставить новый объект по логическому номеру.
3--- Get--- извлечение объекта по логическому номеру.
4--- Print--- вывод всего списка на экран.
5--- Sort--- сортировка списка.
6--- Save--- сохранение списка в файле.
7--- Exit--- завершение и выход из программы.
А теперь рассмотрим сами функции, которые используются в программе.
Функция добавления объекта в конец списка.
int add(T *q)
В функцию передается указатель на объект, значение которого необходимо вставить в список. При добавление происходит проверка на размерность элемента списка
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.