Синтаксичний аналізатор працює шляхом перенесення нуля або декількох символів у стек доти, поки на вершині стека не виявиться основа β. Потім він згортає β до лівої частини відповідної продукції. Синтаксичний аналізатор повторює цей цикл, поки не буде виявлена помилка або він не прийде в конфігурацію, коли в стеку знаходиться тільки стартовий символ, а вхідний буфер порожній.
У цій конфігурації синтаксичний аналізатор припиняє роботу і повідомляє про успішний розбір вхідного рядка.
Пройдемо по кроках всі дії, які виконуються синтаксичним аналізатором при розборі вхідного рядка id1+id2 * id3. Послідовність дій показана в табл. 4.4.
Основними операціями синтаксичного аналізатора являються перенесення і згортання, але фактично ПЗ-аналізатор може виконувати чотири дії: перенесення, згортання, допуск і виявлення помилки.
Таблиця 4.4
Стек |
Вхід |
Дія |
$ $ id1 $E $E+ $E+ id2 $E+E $E+E* $E+E* id3 $E+E*E $E+E $E |
id1+id2 * id3$ +id2 * id3$ +id2 * id3$ id2* id3$ * id3$ * id3$ id3$ $ $ $ $ |
Перенесення Згортання за E →id Перенесення Перенесення Згортання за E →id Перенесення Перенесення Згортання за E →id Згортання за E → E*E Згортання за E → E+E Допуск |
При перенесенні черговий символ переноситься на вершину стека.
При згортанні синтаксичний аналізатор розпізнає правий кінець основи на вершині стека, після чого він повинен знайти лівий кінець основи і прийняти рішення про те, яким нетерміналом замінити основу.
При допуску синтаксичний аналізатор повідомляє про успішний розбір вхідного рядка.
При помилці синтаксичний аналізатор знаходить помилку у вхідному потоці і викликає програму відновлення після помилки.
4.8 LR(k)-аналізатори
У назві LR(k) символ L означає, що розбір здійснюється зліва направо, R – що будується праве породження у оберненому порядку, k – число вхідних символів, які можуть бути переглянуті для прийняття рішення про спосіб проведення розбору. Коли k опущено, мають на увазі 1.
LR-аналіз привабливий з кількох причин.
LR-аналізатори можуть бути побудовані для розпізнавання практично всіх конструкцій мов програмування.
Метод LR-аналізу – найбільш загальний метод ПЗ-аналізу без відкоту, який, крім того, може бути реалізований досить ефективно.
Найбільш відомі три методи побудови таблиць LR-аналізу для граматик. Перший метод, простий LR (simple LR, SLR), є найбільш легким в реалізації, але найменш потужним з них. Він не може побудувати таблицю для розбору деяких граматик, які успішно обробляються іншими методами. Другий метод, канонічний LR, – найбільш потужний, але він потребує найбільших ресурсів. Третій метод – метод з попереднім переглядом (lookahead LR, LALR) за потужністю і споживаними ресурсами займає проміжне положення. Метод LALR працює з більшістю граматик і може бути ефективно реалізованим.
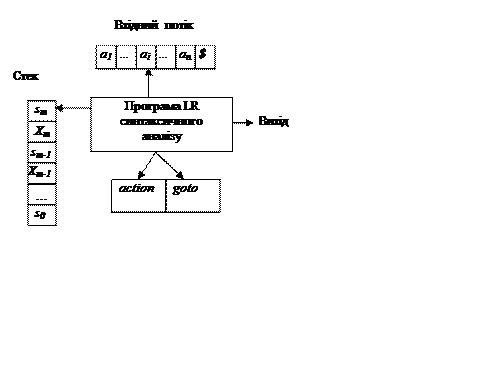
Схематично структура LR-аналізатора зображена на рис.4.5.
LR-аналізатор складається з входу, виходу, стека, керуючої програми і таблиці синтаксичного аналізу, що складається з двох частин – дії (action) і переходу (goto). Керуюча програма одна й та сама для всіх аналізаторів, різні аналізатори розрізняються таблицями аналізу. Програма синтаксичного аналізу читає символи з вхідного буфера по одному за крок.
Рисунок 4.5 - Структура LR-аналізатора
У процесі аналізу використовується стек, у якому зберігаються рядки вигляду s0X1s1X2s2...Xmsm (sm знаходиться на вершині стека). Кожен Xi є символом граматики (термінальним або нетермінальним), а si – символ, який називається станом. Кожен символ стану виражає інформацію, що утримується в стеку нижче його, а комбінація символа стану на вершині стека і поточного вхідного символа використовується для індексації таблиці аналізу і визначає рішення про перенесення або згортання. При реалізації символи граматики не обов'язково повинні з’являтися в стеку. Однак їх використання зручне для спрощення розуміння поводження LR-аналізатора.
Таблиця аналізу складається з двох частин: дій (action) і переходів (goto). Керуюча програма синтаксичного аналізатора функціонує таким чином. Вона визначає sm, поточний стан на вершині стека і поточний вхідний символ ai. Потім програма звертається до action[sm,ai], елемента таблиці дій синтаксичного аналізу, який може мати одне з чотирьох значень:
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.