Побудова таксона в рамках алгоритму Форель відбувається за такою процедурою [69]:
1. Вибирається початкове
розбиття ![]() вибірки Х.
вибірки Х.
2. Будується розбиття ![]() і обчислюється середнє вибіркове
і обчислюється середнє вибіркове ![]() класа
класа ![]() .
.
3. Будується розбиття ![]() , де
, де ![]() Х:
Х: ![]()
![]() Х
Х![]()
4. Якщо ![]() ,
то перехід до пункту 2 (при цьому
,
то перехід до пункту 2 (при цьому ![]() ), інакше приймається
), інакше приймається
![]() і завершення роботи алгоритму.
і завершення роботи алгоритму.
Якщо доповнити
простір W вектором-реалізацією з вершиною ![]() за
умови
за
умови ![]() , то статистичний розкид вибірки Х відносно
множини е= {е,
, то статистичний розкид вибірки Х відносно
множини е= {е, ![]() }, де
}, де ![]() , має вигляд
, має вигляд
F(X; е) = 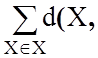 е)2
=
е)2
=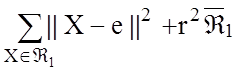 ,
,
де ![]() Х:
Х:![]() ;
;
![]() –
кількість елементів у множині Х\
–
кількість елементів у множині Х\ ![]() .
.
Модифікацією алгоритму Форель є алгоритм Пульсар [70], в якому радіус кулі не фіксується, а адаптується за рекурентною процедурою стохастичної апроксимації. Таксономічні алгоритми типу Краб [69] схожі за структурою до алгоритму Форель, але в них компактність оцінюється за відношенням довжини ребра між двома точками і довжиною мінімального із суміжних йому ребер, яке визначає так звану l-відстань.
Таким чином, для широкого класу алгоритмів автоматичної класифікації, які реалізують задачу відокремлювання в багатовимірному просторі ознак компактних груп точок і в основу яких покладено гіпотезу чіткої компактності, загальними властивостями є використання дистанційних критеріїв типу “найближчого” або “найдальшого” сусіди та, взагалі, відсутність етапу навчання.
Введення у розгляд гіпотези нечіткої компактності реалізацій образу потребує розширення та конкретизації поняття “слабо формалізований процес”, визначення якого щодо задач інженерії знань дано О. Ю Соколовим у праці [140]. Для застосування цього поняття в методах машинного навчання СК розглянемо таке його визначення.
Визначення 1.4.3. Слабо формалізованим процесом називається динамічний процес, що належить до неструктурованих і слабо структурованих проблем керування (за класифікацією Г. Саймона) і має такі характеристики:
· унікальність процесу, пов’язана з моделюванням розумових процесів, властивих людині при прийнятті рішень;
· природа ознак розпізнавання може бути як кількісна, так і якісна;
· неоднорідність (різнотиповість) шкал вимірів ознак розпізнавання;
· імплікативний характер взаємозв’язку характеристик СК;
· багаторівнева ієрархічна організація бази даних і взаємозв’язку підпроцесів;
· різноманіття можливих форм взаємодії підпроцесів між собою, яке породжує неоднорідність інформації, що циркулює в системі;
· багатофакторність і наявність часткових суперечливих критеріїв;
· апріорна невизначеність;
· нечітка, у загальному випадку, компактність реалізацій образу, обумовлена довільними початковими умовами динамічного процесу керування у моменти зняття інформації.
Ігнорування традиційними методами автоматичної класифікації гіпотези нечіткої компактності реалізацій образу дало поштовх для розвитку методів нормалізації образів [78,79,213] з метою їх приведення до “добре організованих” і методів нечіткої класифікації [155-160], які базуються на теорії нечітких множин Л. Заде [155,156]. Незважаючи на досягнуті успіхи в застосуванні методів нормалізації, передусім при розпізнаванні літер і цифр у документах і текстах [214-220], все ще відсутні універсальні методи оброблення зображень, щоб можна було порівняти їх за ефективністю з інтелектуальними можливостями людини.
У працях [221,222] запропонована ітераційна процедура навчання розпізнаванню образів, побудована на основі теорії редукції [211] з використанням принципу дуальності оптимального керування [223]. В основі ітераційної процедури лежить альфа-процедура, яка дозволяє послідовно корегувати простір ознак розпізнавання в процесі його розширення і будувати безпомилкове за навчальною вибіркою лінійне вирішальне правило. За альфа-процедурою початком навчання є виконання умови:
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.