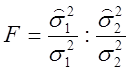
имеет
F-распределение
с r1 и r2 степенями
свободы. Поскольку распределение Фишера асимметрично, то из (2.62) получаем
100(1-![]() )% оценку
)% оценку
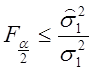 :
: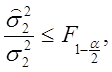 (2.76)
(2.76)
где
![]() -квантили F-распределения. После несложных преобра-зований
с учетом (2.55) приходим к следующему 100(1-
-квантили F-распределения. После несложных преобра-зований
с учетом (2.55) приходим к следующему 100(1-![]() )%
доверительному интервалу для отношения двух генеральных дисперсий
)%
доверительному интервалу для отношения двух генеральных дисперсий
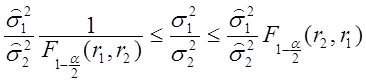 . (2.77)
. (2.77)
В иллюстративных целях рассмотрим следующий пример.
Пусть n1 = 10, n2 = 20. В
качестве оценок ![]() и
и ![]() дисперсий
дисперсий![]() и
и ![]() выбраны выборочные дисперсии
выбраны выборочные дисперсии ![]() и
и ![]() , и по результатам
выборок получены значения
, и по результатам
выборок получены значения ![]()
![]() 90% довери-тельный интервал имеет вид
90% довери-тельный интервал имеет вид
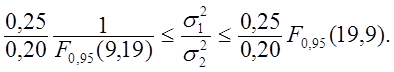
По
таблицам приложения Д находим : ![]()
![]() Таким образом,
Таким образом, 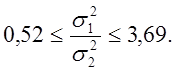 Отметим,
что полученный доверительный интервал содержит 1, и, следо-вательно,
данные согласуются с гипотезой равных дисперсий (см.§2.6).
Отметим,
что полученный доверительный интервал содержит 1, и, следо-вательно,
данные согласуются с гипотезой равных дисперсий (см.§2.6).
Если в (2.76) положить ![]() , т. е.
, т. е.
![]() и
и ![]() - оцен-ки
одной и той же генеральной дисперсии
- оцен-ки
одной и той же генеральной дисперсии ![]() , то в этом случае
, то в этом случае
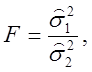
и,
следовательно, F-распределение
может быть использовано для оценки отношения двух оценок одной и той же
дисперсии. Со 100(1-![]() % вероятностью из (2.77) получаем
% вероятностью из (2.77) получаем
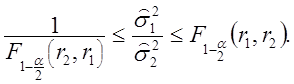 (2.78)
(2.78)
2.5 Проверка статистических гипотез
При построении интервальных оценок генеральных параметров (см.§ 2.4) использовался принцип практической достоверности: события с вероятностью, близкой к 1, считаются практически достоверными. Это позволило не доводить окончательные вероятности до 1 (что дало бы бесконечные интервалы в качестве границ). Принимаемый при этом уровень достоверности назывался доверительной вероятностью р.
Из принципа практической достоверности вытекает принцип практической
невозможности: события с малыми вероятностями,
близкими к 0, считаются практически невоз-можными. В
качестве примера использования этого принципа может служить правило 3![]() в случае нормального распре-деления
(см.§ 2.3).
в случае нормального распре-деления
(см.§ 2.3).
Случайное событие в результате наблюдения может происходить,
а может и не происходить. Практически невозможное событие, таким образом, можно
считать неслучайным. Говорят, что оно является значимым. Использование принципа
практической невозможности для доказательства неслучайного появления события с
малой вероятностью называется принципом значимости. Наибольшее значение вероятности, при котором событие
считается неслучайным (значимым), называется уровнем значимости. Чем выше уровень значимости, тем он “жестче”, ибо
тем большее число событий нельзя рассматривать как случайные. Очевидно, уровень
значимости ![]() и уровень достоверности р как вероятности
противоположных событий в сумме должны давать единицу :
и уровень достоверности р как вероятности
противоположных событий в сумме должны давать единицу :![]()
Значимые события были построены нами в предыдущем параграфе.
Действительно, если ![]() - случайная величина
- случайная величина![]() с известным законом распределения, то при
заданном уровне значимости a можно найти симметричные
относительно медианы распределения квантильные доверительные границы
с известным законом распределения, то при
заданном уровне значимости a можно найти симметричные
относительно медианы распределения квантильные доверительные границы ![]() и
и ![]() (2.62).
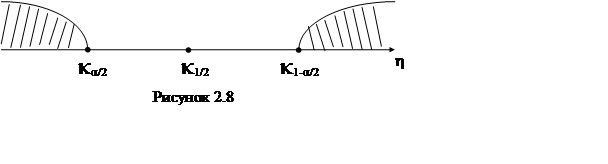
Значения
(2.62).
Значения ![]() , меньшие чем
, меньшие чем ![]() и
большие, чем
и
большие, чем ![]() образуют область G (рис.2.8).
При значениях
образуют область G (рис.2.8).
При значениях ![]() близких
близких
 |
Принцип значимости лежит в основе проверок так назы-ваемых статистических гипотез. Под статистической гипотезой понимают всякое высказывание о виде неизвестного распределения или о параметрах известного распределения. Рассмотрим вторые.
Пусть относительно некоторого генерального параметра q выдвигается гипотеза H0 : q = q0,
где q0 - некоторое число. Такую гипотезу будем называть нулевой. Гипотеза H1 : q ¹ q0
называется альтернативной (конкурирующей).
Гипотеза H0 может быть принята или отклонена на основании результатов наблюдений. Если нулевая гипотеза и данные выборки согласованы, то мы будем считать, что она подтверждается данными; в противном же случае гипотеза H0 не согласована с данными, и мы будем говорить, что они значимо отклоняются от гипотезы.
Принимая решение относительно истинности или ложности гипотезы, мы можем допустить ошибку. Возможные ошибки различаются по своему характеру. Ошибка первого рода состоит в том, что отвергается гипотеза, которая на самом деле верна. При заданном уровне значимости a
Р (отклонить Н0, когда верна Н0)=a,
т. е. вероятность ошибки первого рода достаточно мала. Ошибка второго рода состоит в том, что гипотеза принимается , а на самом деле она неверна
P (принять Н0, когда верна Н1)=b.
Правильное решение также может быть двух родов:
P (принять Н0, когда верна Н0)=1-a;
P (принять Н1, когда верна Н1)=1-b.
Вероятность 1-b=P(H1/H1) называют мощностью критерия.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.