Структура блока: {<идентификатор блока> [{ <заголовок>}] <тело> [{<концевик> }] }.
Так как связи (выход одного блока -> вход другого блока ) определяются согласно варианту только в блоках описаний, то было принято решение не использовать <заголовок> и <концевик>. Таким образом, любой блок разрабатываемого языка содержит: { <идентификатор блока>; <тело>}, где <идентификатор блока>: <Имя блока>:<тип блока>. Имя блока – идентификатор, тип блока: mem, calc или link.
Ниже приведена простая тестовая программа, где используются все элемента языка:
Это блок описания связей между блоками:
{ l1:link;
m1-^out1 to c2->in1;
m1-^out2 to c2->in2;
c1-^out1 to c2->in3;
c2-^out2 to c1->in1;
c2-^out1 to c3->in2;
m2-^out1 to c3->in1;
}
Это блок описания общей памяти:
{ m1: mem;
int IntValue = 13;
double doubleValue = 3.14;
long LongValue = 10000000;
}
Это вычислительный блок, содержащий только арифметические операторы:
{ c2: calc;
c2-^out2=c2->in3+3;
c2-^out1=c2->in1*c2->in2-10;
}
Это вычислительный блок, содержащий арифметические и вложенные условные операторы:
{ c3: calc;
c3-^out1=c3->in1+10*c3->in1;
c3-^out2=c3->in1-10; //это строчный комментарий на русском языке
if (c3->in1==0)
if (c3->in2==0)
c3-^out1=c3->in1+ c3->in2;
c3-^out2=c3->in1- c3->in2;
else
c3-^out1=c3->in1* 10;
end if;
else
if (c3->in2==1)
c3-^out1=c3->in1*3;
c3-^out2=c3->in1/3;
else
c3-^out1=100;
end if;
end if;
c3-^out3=c3->in1;
}
2. Разработать систему регулярных выражений, определяющую лексику заданного варианта языка. Используя пакет WebTransLab, построить автоматную реализацию лексического акцептора. Убедиться в работоспособности акцептора.
Для полного описания лексики разрабатываемого учебного языка используются именованные регулярные выражения, т.е правила вида:
<Наименование группы слов>:<регулярное выражение>
Совокупность таких правил называется системой регулярных выражений, определяющих способ порождения нескольких групп слов.
Ниже приведена разработанная система регулярных выражений:
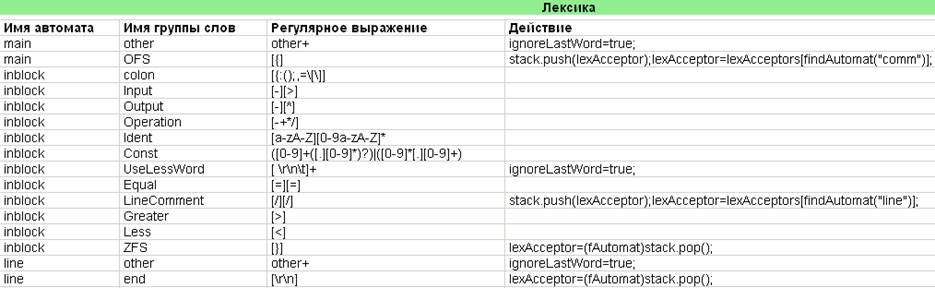
Рис. 1. Система регулярных выражений, определяющая лексику разрабатываемого языка
Примечания:
1) Действие при обнаружении правильного слова из группы UseLessWord, other – присвоить переменной ignoreLastWord значение true, т.е. пропустить данное слово;
2) Данное определение лексики языка предусматривает наличие комментариев между блоками, для этого используются два автомата: main – начинает обработку комментария. При обнаружении открывающейся фигурной скобки на входе переключается на автомат inblock. Автомат inblock определяет регулярные выражения для конструкций внутри блоков программы. При обнаружении закрывающейся фигурной скобки переключается обратно на автомат main.
3) Предусмотрена возможность строчных комментариев, начинающихся с конструкции вида: //. После неё следует комментарий. При обнаружении цепочки символов // происходит переключение с автомата inblockна автомат line, реализующий обработку строчных комментариев. Возврат к автомату inblockпроисходит при обнаружении символов возврата каретки и перевода строки.
Таким образом, выполнено требование того, что текст между блоками считается комментариями.
Созданная система регулярных выражений может быть преобразована в оптимальный конечный автомат без памяти, способный распознавать правильные слова всех заданных групп. В таком случае, каждой группе слов сопоставляется в точности одно финальное состояние, номер которого при останове автомата используется для идентификации той группы, в которую входит обнаруженное слово.
Используя пакет WebTransLab, построим автоматную реализацию лексического акцептора и убедимся в его работоспособности на примере разбора простой тестовой программы, содержащей все заданные элементы языка:
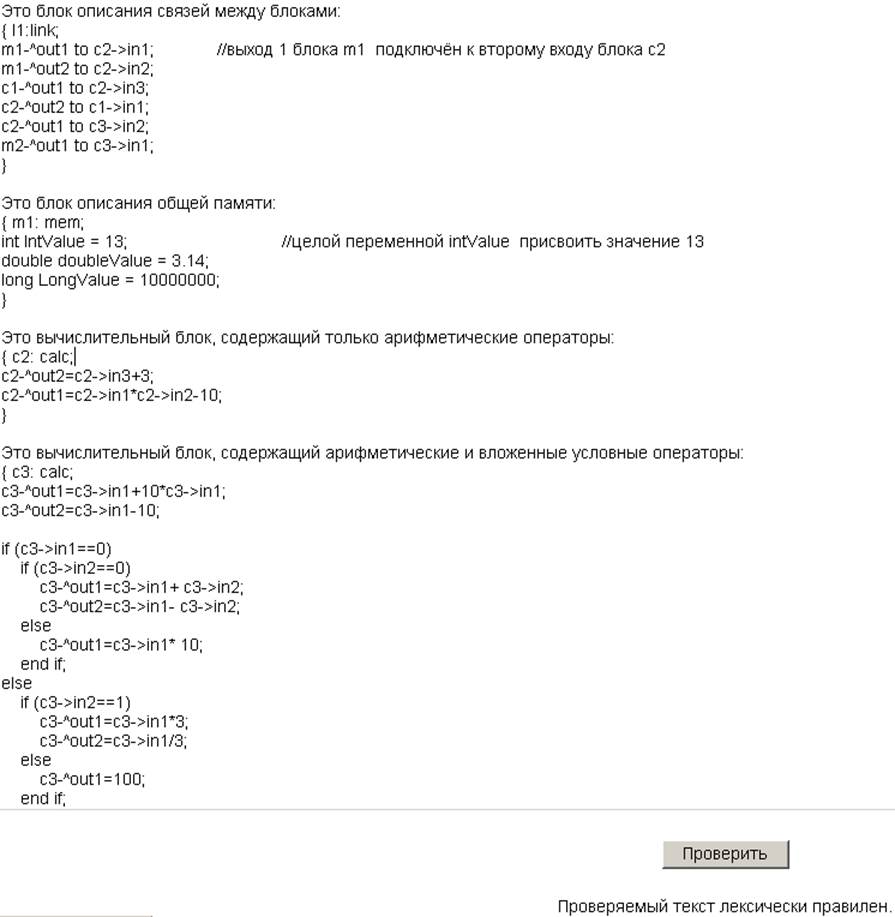
Рис. 2 Проверка работоспособности автоматной реализации лексического акцептора
Допустим, при написании программы была совершена ошибка следующего вида:
В вычислительном блоке с3 результат на выходе out1 равен произведению значения на входе in1 и числа 10, т.е.
c3-^out1=c3->in1*10; а с ошибкой текст описания блока выглядит следующим образом: c3^-out1=c3->in1*10 (неправильно указан выход блока c3, перепутаны ‘–‘ и ‘^’). Посмотрим на работу лексического акцептора:


Рис. 3 Работа лексического акцептора в случае лексической ошибки
Таким образом, лексический акцептор просто проверяет цепочку из одного или более символов на предмет принадлежности к какой-либо из объявленных групп слов. Программа признаётся правильной с лексической точки зрения, если все символы/цепочки символов «принадлежат» системе регулярных выражений, определяющих лексику заданного языка.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.