}
ungetCharIgnoreLineEnd('!');
}
if (matchChar('<')) {
if (matchChar('=')) {
return Token.ASSIGN_LSH;
} else {
return Token.LSH;
}
} else {
if (matchChar('=')) {
return Token.LE;
} else {
returnToken.LT;
}
}
case '>': //с литеры > начинаются одно-, двух-, трех- и четырехлитерные слова языка
if (matchChar('>')) {
if (matchChar('>')) {
if (matchChar('=')) {
return Token.ASSIGN_URSH;
} else {
return Token.URSH;
}
} else {
if (matchChar('=')) {
return Token.ASSIGN_RSH;
} else {
return Token.RSH;
}
}
} else {
if (matchChar('=')) {
return Token.GE;
} else {
return Token.GT;
}
}
case '*':
if (matchChar('=')) {
return Token.ASSIGN_MUL;
} else {
returnToken.MUL;
}
case '/': //с литеры / кроме значащих слов могут начинаться и однострочные и блочные (возможно – многострочные)
//комментарии; ниже следует анализ продолжения входной цепочки с фиксацией возможных ошибок
// is it a // comment?
if (matchChar('/')) {
skipLine();
continue retry;
}
if (matchChar('*')) {
boolean lookForSlash = false;
for (;;) {
c = getChar();
if (c == EOF_CHAR) {
parser.addError("msg.unterminated.comment");
return Token.ERROR;
} else if (c == '*') {
lookForSlash = true;
} else if (c == '/') {
if (lookForSlash) {
continue retry;
}
} else {
lookForSlash = false;
}
}
}
if (matchChar('=')) {
return Token.ASSIGN_DIV;
} else {
returnToken.DIV;
}
case '%': //далее, вплоть до case '-' следует обработка одно- и двухлитерных слов
if (matchChar('=')) {
return Token.ASSIGN_MOD;
} else {
return Token.MOD;
}
case '~':
return Token.BITNOT;
case '+':
if (matchChar('=')) {
return Token.ASSIGN_ADD;
} else if (matchChar('+')) {
return Token.INC;
} else {
return Token.ADD;
}
case '-': //с литеры «-» могут начинаться знак операции вычитания (-), присваивания с вычитанием (-=),
//декремента (--) и конец HTML-комментария (-->)
if (matchChar('=')) {
c = Token.ASSIGN_SUB;
} else if (matchChar('-')) {
if (!dirtyLine) {
// treat HTML end-comment after possible whitespace
// after line start as comment-utill-eol
if (matchChar('>')) {
skipLine();
continue retry;
}
}
c = Token.DEC;
} else {
c = Token.SUB;
}
dirtyLine = true;
returnc;
default: //с любой из остальных литер никакое правильное слово языка начинаться не может:
parser.addError("msg.illegal.character");
returnToken.ERROR;
}
}
}
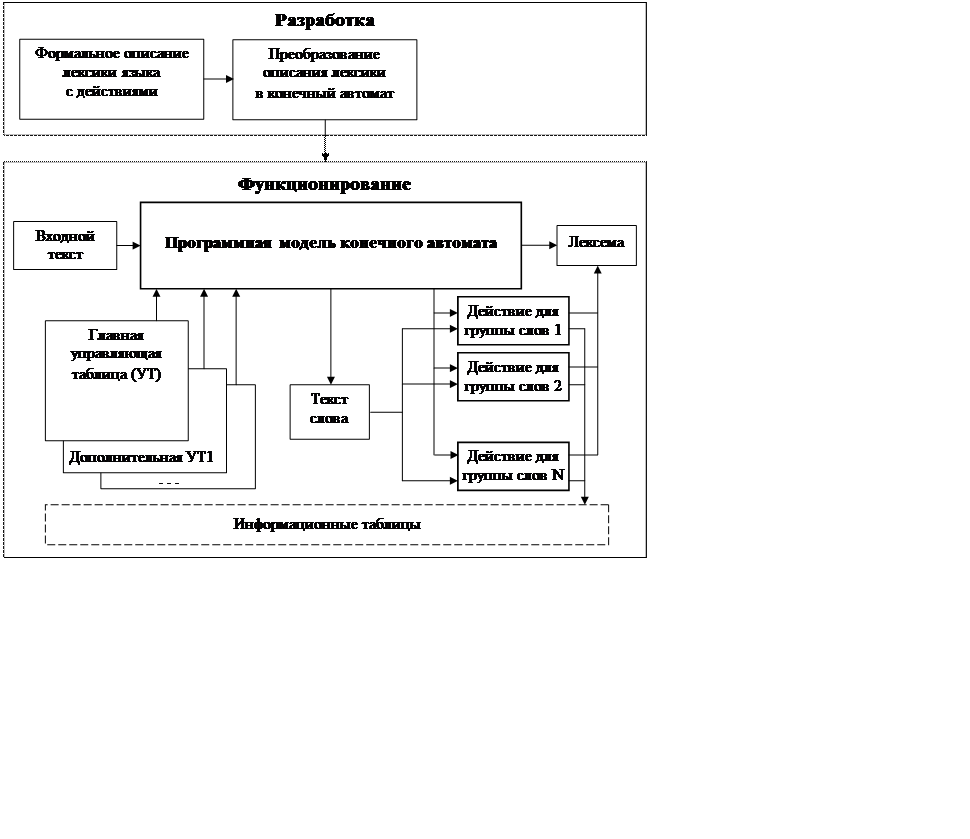
Автоматный способ реализации лексического анализатора.
 |
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.