5. Пакет программ анализа данных SPSS, использованный в [3] для кластерного анализа, позволяет в автоматическом режиме выполнять отбор переменных, входящих в регрессионную модель [10]. «Реконструкция» регрессионного анализа с устранением имеющихся в них ошибок (уровень занятости населения в одном из наблюдений больше 100%, сумма составляющих структуры уровня образования в ряде случаев не равна 100%) позволила авторам статьи [1] получить регрессионную модель вида:
у = 29,122 - 1,132х3 + 1,468х7 - 0,252х8, (1)
где х3 — доля лиц со средним профессиональным образованием, %; х7 — уровень безработицы, %; х8 — доля оплаты труда в себестоимости, %.
Данная модель объясняет 59,2% дисперсии и характеризуется стандартной ошибкой аппроксимации 0,92%, что отвечает средней погрешности предсказания 23,8%. Данная модель с тремя предикторами отлична от модели, полученной в [3] и имеющей вид:
у = -5,084+0,083х1+0,199х2-0,910х3+0,233х4+0,463х5+0,023х6+1,317х7-0,288х8,
где дополнительно присутствуют следующие предикторы: х1 - уровень занятости населения, %; х2 - доля лиц с высшим образованием, %; х4 - доля лиц со средним образованием, %; х5 - доля лиц с неполным средним образованием, %; х6 - соотношение начисленной номинальной среднемесячной заработной платы и минимального потребительского бюджета, %; х8 - доля оплаты труда в себестоимости, %.
6. Заметим, что знаки коэффициентов регрессии при предикторах х3, х7 и х8 у обеих моделей совпадают, и они дают близкие результаты прогноза значений уровня рентабельности. Однако данных о точности аппроксимации модели 2 в работе [3] нет (в ней лишь указано, что она объясняет 63,8% использованных факторов), что ненамного превышает значение 59,2% для модели 1. Однако если даже допустить, что эта модель корректна, ей на практике следует предпочесть более простую модель вида (1).
7. Модель вида (1) адекватна (остатки распределены по закону, близкому к нормальному, критерий Фишера значим на уровне не хуже 0,0005), но ее прогностические свойства, как и ранее полученной модели, оставляют желать лучшего (на рис. 1 отражена взаимосвязь предсказанных и фактических значений рентабельности).
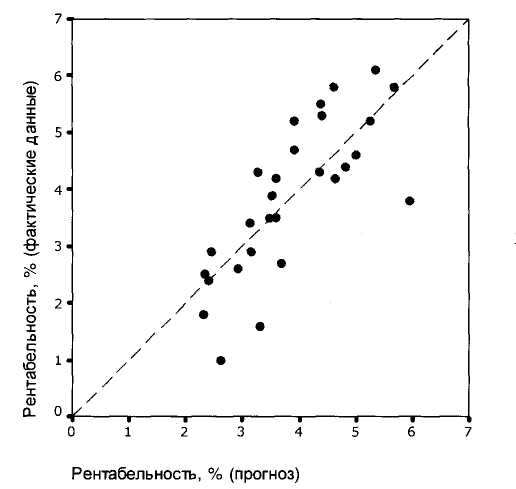
Рис. 1. Взаимосвязь предсказанных и фактических значений
рентабельности регионов Белоруссии по модели (1)
8. Сравнение приоритетов изучаемых факторов по степени их влияния на результативный признак непосредственно по величине коэффициентов регрессии проводят лишь в некоторых частных случаях. В общем случае для этого необходим расчет коэффициентов эластичности либо сравнение бета-коэффициентов, нормированных на величину стандартных отклонений соответствующих переменных. Учитывая, что в вышеприведенных моделях переменные имеют размерность «проценты», интерпретация в [3] коэффициентов регрессии как «сравнительная сила влияния факторного признака на рентабельность региона» в принципе обоснованна. Однако из-за мультиколлинеарности и, как следствие, смещенных оценок коэффициентов регрессии подобный анализ вряд ли имеет смысл.
9. Кроме того, выявление статистических закономерностей не является основанием для содержательных выводов: наличие корреляции не означает наличия причинной связи. Это - аксиома, и ее не следует даже напоминать. Но в работе [3] приводится экономическое обоснование каждого коэффициента регрессии модели, что некорректно, так как:
а) увеличение уровня рентабельности с ростом безработицы объясняется тем, что уменьшение численности слабо занятых работников способствует повышению рентабельности (очевидно, имеется в виду переход скрытой безработицы в официально регистрируемую безработицу);
б) положительный знак коэффициента регрессии при предикторе х5 (доля лиц с неполным средним образованием) связывается с повышением образования работников с уровня начального (4 класса) до базового (9 классов), способствующим росту рентабельности и др.
10. Обсуждаемая модель из [3] получена на весьма ограниченных данных: наблюдения охватывают только семь регионов, а период наблюдений составляет лишь 4 года (1998-2001). Использование такого приема увеличения объема выборки в принципе возможно, но при этом увеличивается опасность получения смещенных оценок коэффициентов регрессии из-за коррелированности данных во времени.
11. Анализ пространственно-временных данных принципиально невозможен без включения в состав предикторов временной переменной. Неочевидно, что региональная дифференциация результативного признака настолько велика, что фактором времени можно пренебречь априорно. Действительно, включение в анализ в дополнение к предикторам х1,..., х8 временной переменной t, определяемой соотношением: t = год – 1998.
12. Последующий регрессионный анализ показал, что статистически значимыми оказываются лишь два предиктора: временная переменная t и соотношение начисленной номинальной среднемесячной заработной платы и минимального потребительского бюджета (x6 , %):
у = 2,051 - 0,899t + 0,02487х6. (2)
Модель 2 объясняет 51,2% общей дисперсии и характеризуется стандартной ошибкой аппроксимации 0,99%.
13. Важный этап эконометрического моделирования - проверка адекватности модели, для чего часто используют визуальный просмотр графиков «Наблюдения - предсказанные значения» или «Остатки - предсказанные значения». Это позволяет увидеть «выбросы» или же отклонения от гомоскедастичности остатков. Из графика «Остатки — предсказанные значения» (рис. 2) следует, что наблюдения 5 и 17 подлежат проверке на корректность.
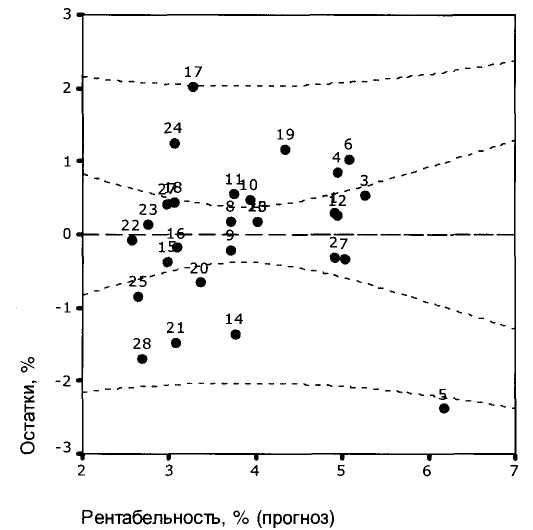
Рис. 2. Зависимость остатков от предсказанных значений рентабельности регионов Белоруссии по модели 4
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.