RISC – процессоры позволяют достигнуть “того же” быстродействия при меньшем объеме оборудования (транзисторов) и при более простой структуре процессора ценой увеличения длины кода (тот же алгоритм реализуется большим количеством команд, но каждая команда выполняется быстрее, чем раньше, и , возможно, средняя длина команды меньше, так что и длина кода эквивалентной программы в RISC также может быть короче).
1) Конвейеризация – увеличение количества этапов выполнения команды
2) Суперскалярность – увеличение количества потоков
3) Предсказание переходов (CD)
4) Условное (спекулятивное)исполнение speculative execution (CD)
5) Предикатные команды (CD)
6) Декодирование в uops и кэш-память uops для исключения повторного декодирования
7) Переименование регистров (FD)
8) Регистровые окна (увеличение скорости переключения контекста)
9) Нарушение естественного порядка следования команд (TD) – параметр – длина окна «просмотра»
10) Оптимизация программы с учетом особенностей структуры конкретного процессора
11) Архитектура с “длинным командным словом” (VLIW –Very Large Instruction Word)
12) Динамическая трансляция исполняемого кода (Transmeta Crusoe, IBM DAISY)
13) Поддержка кластерных архитектур
1) и 2) сводятся к увеличению количества
параллельно работающих исполнительных блоков. При этом основное препятствие –
загрузка этих устройств полезной работой. Два крайних подхода:
а) динамическая загрузка путем исследования кода на стадии
исполнения и
б) статическая загрузка на этапе компиляции программы (WLIV).
3) , 4) и 5) предназначены для уменьшения влияния зависимостей по управлению.
Предсказание переходов делается статически или динамически, на основании статистики предшествующего выполнения программы. Качество предсказания улучшается с увеличением анализируемого объема статистики. Это определяется объемом буфера предсказания ветвлений (Branch Target Buffer BTB).
Условное исполнение предполагает исполнение кода по предсказанной ветви, либо даже одновременно по нескольким ветвям с последующим выбором нужной ветви после разрешения условия перехода. Исполнение по нескольким ветвям становится возможным в процессоре с переименованием регистров, так как позволяет исключить влияние зависимостей по ресурсам (регистрам процессора).
Предикатные команды расширение понятия флажков (признаков). Вместо использования комбинации
1)команда,
изменяющая флаги
2)команда условного ветвления, обходящая действие
3)команда, реализующая действие
…)следующие команды …
используются условные (предикатные) команды, которые, в зависимости от того, установлены ли указанные флаги, либо производят действие, либо ведут себя, как команда NOP. В процессорах с предикатными командами обычно используется несколько комплектов флагов, либо специальные предикатные биты. Комбинация предикатных команд, эквивалентная вышеприведенной, выглядит так:
1)команда,
изменяющая флаги (заданный их экземпляр,
либо заданные предикатные биты)
2)предикатная команда (она в зависимости от состояния
флагов/предикатных битов
выполняет операцию, либо не делает ничего)
…)следующие команды …
В процессоре с предикатными командами удается уменьшить количество команд (в приведенном примере две вместо трех), и одновременно избежать условного ветвления, т.е. зависимости по управлению.
Декодирование в микрооперации (аппаратная трансляция команд уровня Programming Model) в более мелкие единицы исполнения. Микрооперации имеют более простую и более унифицированную структуру, и, таким образом могут быть легче аппаратно реализованы, лучше конвейеризуются, и т.п. В некоторых современных процессорах (например, Pentium4) кэш-память команд заменена кэш-памятью микроопераций, что позволяет сэкономить время на декодировании при выполнениии программных циклов).
Переименование регистров – физический регистровый файл содержит больше регистров, нежели регистровая модель для программиста. Например, в PentiumPro+ регистровый файл содержит 40 (32-битовых) регистров, в то время как программная модель – только 8. Если данный экземпляр регистра занят (False Dependency), то следующая команда исполняется, используя другой экземпляр регистра.

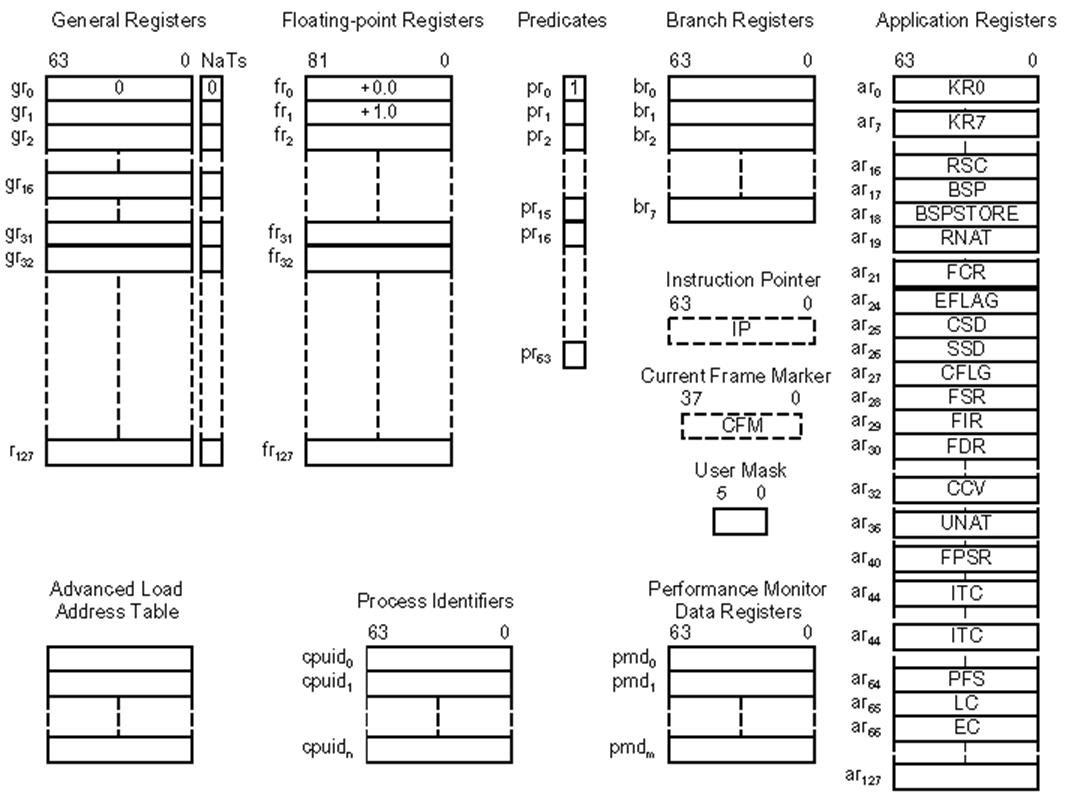
Регистровые окна – прием, похожий на переименование регистров, состоящий в том, что логические имена регистров (r0, r1,…) могут сдвигаться по регистровому файлу при обращении к подпрограмме либо при входе в прерывание. Т.е. фактически, после входа будут (с теми же именами) использоваться другие экземпляры регистров (например, в IA64). Этот прием исключает необходимость классического сохранения-восстановления контекста.
Нарушение естественного порядка следования команд – при возникновении True Dependencies, когда следующая команда не может продолжить выполнение, процессор просматривает поток команд и направляет на выполнение те, которые могут выполняться. Окончание выполнения команд происходит в том порядке, который предусмотрен в программе.
Оптимизация программного кода с учетом особенностей структуры процессора может осуществляться
а) программистом вручную (особенно для критических по
скорости выполнения участков кода),
б) оптимизирующим компилятором,
в) аппаратно во время выполнения
Архитектура с длинным
командным словом – см. архитектуру IA64,
разработку IBM DAISY, процессор фирмы Transmeta
Crusoe
Динамическая трансляция в машинный код – преобразование «на лету» исполняемого кода одной архитектуры в исполняемый код другой (обычно имеющей более высокую степень внутреннего параллелизма и быстродействие) – обеспечивает одновременно совместимость и повышение скорости исполнения – см. – см. разработку IBM DAISY, процессор фирмы Transmeta Crusoe

[АПН1] Не всегда. Даже собрав вместе девять беременных женщин, мы не добьемся рождения ребенка через месяц.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.